The TopBraid platform can be used to build all kinds of applications and solutions. We've recently noticed one particular area where more and more customers needed help, and where semantic technology and our tools were a great fit: the management of multiple connected vocabularies spread out across an enterprise. To meet this need, we've created TopBraid Enterprise Vocabulary Net (EVN), a solution that works out of the box while having all the power of TopBraid Suite behind its customization capabilities. The EVN product page has a long list of its features, which provide everything you need to manage taxonomies and thesaurii (and even create simple ontologies) in multi-user environments. The ability to review proposed changes before rolling them into production, with a choice of reports and other options for analyzing those changes and their potential impact, will be especially useful in larger organizations. The use of EVN requires no knowledge of SKOS, RDF, or the related W3C standards, but the use of these standards behind EVN's graphical user interface is what makes EVN both flexible and scalable. The use of public standards for data, models, and application logic makes it much easier to integrate EVN with other systems than any other vocabulary management solutions we've seen in the marketplace. They also make it easier for EVN to let you set up an environment where different vocabularies in different parts of a large organization can work cooperatively with no need to merge those vocabularies into a single large, central vocabulary. EVN is included in TopBraid Composer Maestro Edition release 3.4, which is now in beta, so you can try it without purchasing a separate product. For a quick overview of the features and what the product looks like, start with thescreenshot tour, or jump right in to the tutorial included with EVN's documentation.![]()
Wednesday, October 27, 2010
TopQuadrant's new Enterprise Vocabulary Manager
Monday, October 4, 2010
How to: read RSS and RDFa from the web with a SPARQLMotion script
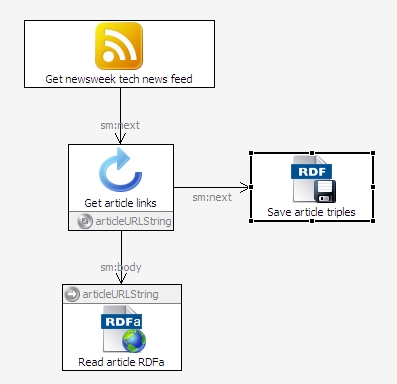
How do you get a SPARQLMotion script to read an RSS or Atom feed as RDF triples? How do you get a SPARQLMotion script to read triples that have been embedded into web pages using RDFa? The answer to both questions is the same: use the specialized SPARQLMotion module for the task. All you have to do is specify the URL of the file with the information you want to read. To demonstrate both, we'll put together a short script that: Reads the RSS feed about technology news from Newsweek magazine Pulls the triples from the RDFa embedded in the Newsweek articles described in the feed Saves the extracted triples in a Turtle file Along with Dublin Core properties such as dc:title and dc:description, RDFa attributes in Newsweek articles store additional RDF metadata using the Open Graph vocabulary developed by Facebook. This makes it easier for Facebook to incorporate additional information about news articles in their applications—for example, if people click the Facebook button next to a Newsweek article in order to share it with their Facebook friends. It also makes it easier for you to use information about these articles in your own applications. The sample application below just saves the retrieved triples in a file, but you could also pass them to other SPARQLMotion modules that could have OpenCalais analyze the text, combine the triples with data from another source, create a new, specialized RSS feed or SPARQL endpoint, or send an email message based on the results of your processing. Retrieving the data is just the beginning. To create this application, start by creating a new SPARQLMotion file called getnewsweektech. (For more detailed background on the steps involved in creating and running a SPARQLMotion script, see the PDF tutorial TopBraid Application Development Quickstart Guide.) Create a new SPARQLMotion script in your getnewsweektech.n3 file. For its first module, select sml:ImportNewsFeed from thesml:ImportFromRemoteModules category and name it GetNewsweekTechNewsFeed. To configure it, you only need to set its sml:url value tohttp://feeds.newsweek.com/newsweek/technology?format=xml, a URL I learned about from Newsweek's web page about their RSS feeds. Once this module pulls down the RSS data and TopBraid converts it to triples, your script will look through these triples for web page URLs provided as RSS link values and then retrieve the triples that are stored as RDFa in those web pages. The script can't pull the triples from all those web pages at once, so we'll use an IterateOverSelect module to drive the next step. We'll specify a SPARQL SELECT query in the IterateOverSelect module to find the RSS link values, and then for each result that this SELECT query finds, another module will retrieve the triples from the web page named by the link value. Drag an Iterate over select module from the Control Flow section of the SPARQLMotion palette and name it GetArticleLinks. Paste the following query in as the value for its sml:selectQuery property: The module that retrieves the RDFa needs a string version of the URL to specify where it should look for the RDFa, so the query above assigns a string version of each rss:item resource's rss:link value to the variable ?articleURLString. The script will execute the body of the IterateOverSelect (a separate module that we haven't created yet) once for each value bound to this variable. You're done configuring this module. Next, we'll create the body of the IterateOverSelect. This can be a series of modules, but for this application we'll only need one. Drag anImport RDFa module from the Import from Remote section of the SPARQLMotion palette and name it ReadArticleRDFa. When configuring this new module, click the white triangle for its sml:url property's context menu and select Add SPARQL expression. This lets you add any combination of SPARQL keywords, symbols, function calls, and operators that returns a single value; for this, all you need here is the variable reference ?articleURLString. Each time this module retrieves triples from the RDFa in the web page at this URL, it will pass along the triples that it found to the next module. If this module has an sml:needsTidy property, set it to True to make it easier to read RSS that isn't well-formed XML. For our script's last module, drag an Export to RDF File module from the palette's Export to Local section and call it SaveArticleTriples. Set its sml:targetFilePath value to newsweekTech.n3; it will write this file to the directory that holds the SPARQLMotion file with your script. Set the module's sml:baseURI to http://example.com/newsweek/tech/metadata or to any URI that you like. All that's left is to connect up the four modules as shown below. When you add a connector out of your Get Article Links Iterate Over Selectmodule, TopBraid Composer will ask you whether your new connector is pointing at the body of the loop (the part to execute for each binding of the selected variable) or at the module that should take control of the script when the iteration is finished. Connect Get Article Links to the Read Article RDFa module with an sm:body link, because that's the part we want executed for each iteration, and connect Get Article Links to Save Article Triples with an sm:next link to transfer control (and the collected triples) there when the iteration is all done. Select the Save Article Triples module and click the green triangle at the top of the workspace to execute the script up to that final module, and you should end up with a newsweekTech.n3 file in the same directory as your getnewsweektech.n3 file that holds the script. This new file will hold triples extracted from the various web pages named in the Newsweek tech news feed. To branch out, you could substitute the names of other Newsweek feeds, or additional ones, and then collect all the triples together. You could drive the whole thing with a TopBraid Ensemble interface where an end user picks the category of Newsweek news (for example, their technology, politics, business, or entertainment categories) whose metadata should be retrieved. You could also find other publications that store RDFa metadata in their articles, or other websites, such as TopQuadrant's. And, as I mentioned earlier, you could combine this with other features of SPARQLMotion and TopBraid to make a very powerful application.PREFIX rss: <http://purl.org/rss/1.0/>
SELECT ?articleURLString
WHERE {
?s a rss:item .
?s rss:link ?articleURL .
LET (?articleURLString := xsd:string(?articleURL)) .
}