
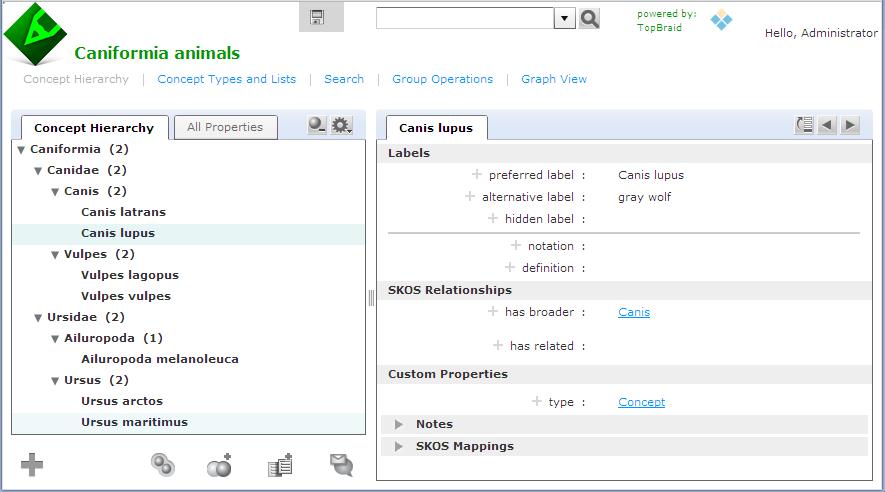
In an earlier entry, we learned how SPARQL Rules can increase the quality of taxonomies and other controlled vocabularies stored using the W3C SKOS ontology. (As I wrote there, the Simple Knowledge Organization Systemvocabulary management specification is gaining popularity because, as a standard, it makes it easier to share taxonomies and thesaurii between different systems. It also guards investments in vocabulary development against the potential problems of dependence on a proprietary vendor format.) TopQuadrant's Enterprise Vocabulary Net (EVN) vocabulary manager uses SKOS as its default format for storing data. Whether you use EVN or not, a first step in systematic management of vocabularies is often the conversion of vocabularies stored in ad hoc spreadsheets—an unfortunately very popular way to store them—to SKOS, so today we'll look at how TopBraid makes this conversion easy. Below is an Excel spreadsheet with some data about a few Caniformia animals. (In the Linnaeus classification of animals, Caniformia is the suborder of Carnivora, which is an order of the Mammalia class.) It shows two families of this suborder and a few genuses and species of each family, with both the Latin and common name of each species. Using a SPARQLMotion script, the basic steps of converting a spreadsheet like this to SKOS are: Read in the spreadsheet as a set of RDF triples. Use a CONSTRUCT query to convert the spreadsheet triples to SKOS triples. This is the step that varies the most from one conversion to another, because people can arrange spreadsheets any way they want, so the logic of the CONSTRUCT query has to infer the correct relationships between the values on the spreadsheet. Save the SKOS triples as an RDF file or in whatever format is appropriate to your applications that will use this data. The following shows the SPARQLMotion script that I used to convert the spreadsheet above. It has a module for each of the three steps listed above and an additional SetBaseURIStr module to set a ?baseURIStr variable. The script refers to the base URI of the output several times, and instead of hardcoding it in all those places, I decided to use this module to set this variable and to then reference the variable from other places so that resetting the base URI could be done in one place. The "set BaseURIString" module has a very simple SELECT query: When you import an Excel file into TopBraid, the "Import Excel Cell Instances" SPARQLMotion module can pull triples from the spreadsheet with information such as the fact that a given cell has a row value of 7 (using zero-based counting), a column value of 0, a type value of "xsd:string", and "giant panda" as its contents. This level of detail can be useful for picking apart complex spreadsheets, but for simpler ones, if you instead use an "Import RDF from Workspace" module (in other words, if you have the script open the spreadsheet as if it were an RDF file), TopBraid uses the headings of the spreadsheet to identify more of the semantics of the data. For example, it would create triples saying that the thing identified as Row-6 has a commonName value of "giant panda" and a genus value of "Ailuropoda". This will be easier to convert to SKOS with a CONSTRUCT query. There are five basic tasks that the conversion module must perform, all through the creation of triples: Declare that the dataset being created is an ontology. Import the standard W3C SKOS ontology so that we can reference its classes and properties. Declare a concept scheme. A SKOS vocabulary can have as many concept schemes as you like, but we'll just create one for our example. Declare concepts for each species, genus, and family found in the input triples, with a skos:broader property pointing from each one to either the appropriate broader concept or, if there is none, to the concept scheme created in the previous step. Create triples that attach any additional metadata to the appropriate concepts—in this case, to assign the common name value to each species concept. SKOS is very flexible, so if you had additional non-SKOS properties specific to your own applications that you wanted to assign to each concept, the steps would be similar to the ones for attaching the common name values from this spreadsheet to each concept. Whe the "Import RDF from Workspace" module reads in a spreadsheet such as caniformia.xls, it uses the spreadsheet's filename to define a prefix for the spreadsheet's properties so that it can refer to those properties with names like caniformia:genus. After opening the spreadsheet directly in TopBraid Composer, I saw that the base URI created for the data and associated with the caniformia: prefix was file:///xls2skos/caniformia.xls, because I had it in a project named xls2skos. I wanted to use this prefix in my SPARQLMotion script's CONSTRUCT query, so I associated this URI with the caniformia: prefix in the Overview tab of the xls2skos.n3 file that stored the SPARQLMotion script. The actual conversion takes place in the Apply Construct module that I named "convert XLSData". These modules can store multiple CONSTRUCT queries, so I used two. The first does the basic setup of the taxonomy being created, which are the first three of the five tasks listed above: The second query performs steps 4 and 5: In addition to creating a SKOS concept for each species, it creates one for each genus and family as well, using the skos:broader property to identify the connections between these concepts that make up the hierarchical taxonomy of terms. One big decision to make with this query was how to create URIs that provided unique identifiers for each new concept being created. I knew that the species, family, and genus names must be unique, so I added those to the base URI after passing them to smf:encodeURL(), a SPARQLMotion extension function that escapes any characters that won't work well in a URI. If you have taxonomy data in a spreadsheet, there may already be a unique number or other form of ID assigned to some or all taxonomy terms that your conversion can grab so that you don't have to create URIs from the names on the spreadsheet like I did. I also decided to use species names like "Canis lupus" as the skos:preferredLabel value in the output and to use labels from the spreadsheet's "common name" column like "gray wolf" as skos:altLabel values. If you wanted to to use common name values as preferred labels and species names as alternative labels, it would be a simple change to the query above. My "convert XLSData" module also has its sml:replace value set to True so that it doesn't pass along the input triples to the final module, which saves the conversion result. This last module, which I named "Save as TDB", is an "Export to TDB" SPARQLMotion module that saves the conversion results using the Jena TDB format. I could have used a SPARQLMotion "Export to RDF" module, which saves triples as a Turtle or RDF/XML disk file, but I wanted to use the results of my conversion in EVN. EVN requires that you use Jena's TDB or SDB formats so that it can attach metadata to your work to support reporting and workflow tracking. After running the conversion, here is one view of it in EVN: This is a minimal example using a small spreadsheet with no non-SKOS metadata. If your spreadsheet includes columns for data that don't fit easily into the SKOS model, you can use TopBraid Composer to create a customized version of SKOS that includes your own properties, and your SPARQLMotion script's conversion module can then add triples for those properties to the result. Viewing them in EVN, they would appear under Custom Properties on the right. And of course, the screen shot above only hints at all that EVN lets you do with your controlled vocabulary once you convert it to SKOS.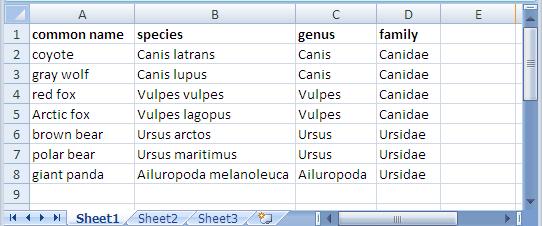

SELECT ?baseURIStr
WHERE {
LET (?baseURIStr := "http://example.com/taxonomies/animals") .
}CONSTRUCT {
?baseURI a owl:Ontology .
?baseURI owl:imports <http://www.w3.org/2004/02/skos/core> .
<http://example.com/taxonomies/animals/caniformia> a skos:ConceptScheme .
<http://example.com/taxonomies/animals/caniformia> rdfs:label "Caniformia" .
}
WHERE {
LET (?baseURI := smf:buildURI("<{?baseURIStr}>")) .
}CONSTRUCT {
?speciesURI a skos:Concept .
?genusURI a skos:Concept .
?familyURI a skos:Concept .
?speciesURI skos:prefLabel ?speciesName .
?speciesURI skos:altLabel ?commonName .
?speciesURI skos:broader ?genusURI .
?genusURI skos:broader ?familyURI .
<http://example.com/taxonomies/animals/caniformia> skos:hasTopConcept ?familyURI .
}
WHERE {
?row caniformia:commonName ?commonName .
?row caniformia:species ?speciesName .
LET (?species := smf:encodeURL(?speciesName)) .
LET (?speciesURI := smf:buildURI("<{?baseURIStr}#{?species}>")) .
?row caniformia:genus ?genusName .
LET (?genus := smf:encodeURL(?genusName)) .
LET (?genusURI := smf:buildURI("<{?baseURIStr}#{?genus}>")) .
?row caniformia:family ?familyName .
LET (?family := smf:encodeURL(?familyName)) .
LET (?familyURI := smf:buildURI("<{?baseURIStr}#{?family}>")) .
}
Wednesday, December 29, 2010
How to: convert a spreadsheet to SKOS
Wednesday, November 10, 2010
Getting started with SPARQL Web Pages
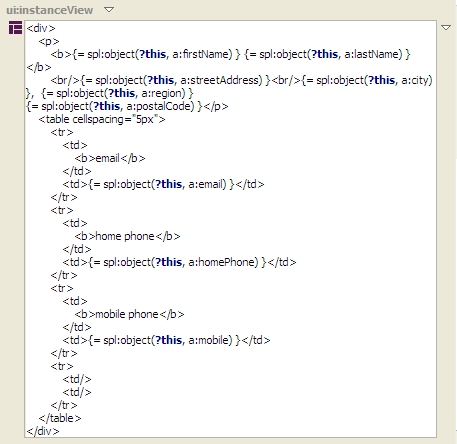
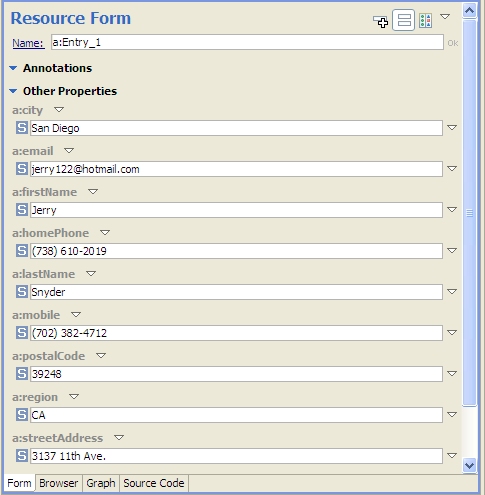
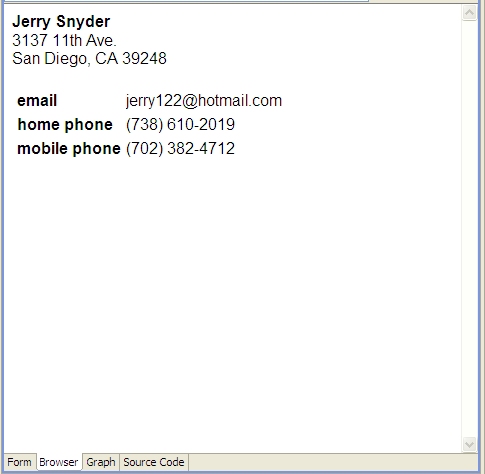
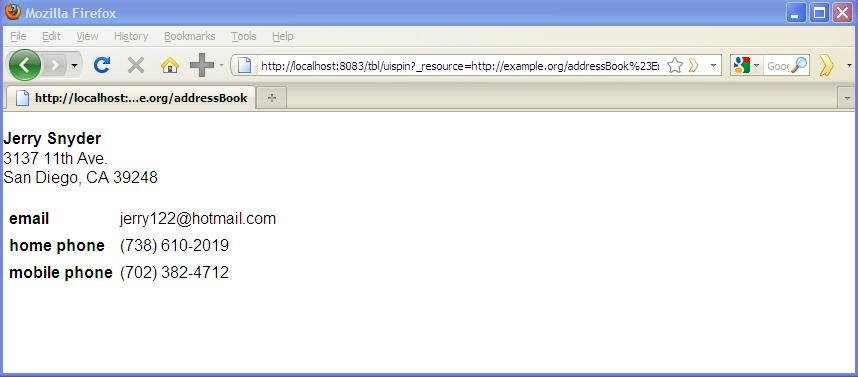
In earlier entries on this blog, we've seen how SPARQL Rules attached to classes can let you identify constraint violations in instances of those classes and implement other kinds of business logic, all using the SPARQL standard. With release 3.4, which is now in beta, TopQuadrant products have another new application of SPARQL that lets you attach useful metadata to class definitions: descriptions of how you want the class's instances to look in a browser. We call this SPARQL Web Pages. TopQuadrant vice president of product development Holger Knublauch has written several blog entries introducing SPARQL Web Pages under its original name, UISPIN, such as UISPIN: Creating HTML and SVG Documents with SPARQL, Charts and Business Reports with UISPIN, and UISPIN Example: Documenting SPIN Functions. In this blog entry, we'll see how to get started with a simple but useful example. Address book information is not as simple to represent in RDF as one might think. A street address, city name, and postal code should be shown in a specific order, but RDF facilities for ordering the property values for a given instance can add annoying layers of complexity to a data model. Without ordering, though a simple address book entry can be difficult to read, like the following fake address shown in Turtle format: Using TopBraid Composer Maestro Edition, I created an RDF file with an Entry class for address book entries. I declared the properties shown above, with the Entry class as their domain, and then I added a few fake address book instances to the file. The file has a base URI of http://example.org/addressBook, which will be important later. Next, I imported the html.rdf model from the UISPIN folder of the TopBraid project that is automatically added to every workspace. (In a production application, especially if I was working with a standard ontology instead of a hand-crafted little model defining an address book entry, I'd create a new file that imported the standard class and property definitions as well as html.rdf instead of adding the SPARQL Web page definitions directly into the file that defines the address book model.) The UISPIN folder also includes models to generate SVG, charts, and more; the html.rdf file lets you add HTML-generating SPARQL code to your classes. Below, you can see how I've added the ui:instanceView property from this file's model to the definition of my Entry class: When I scroll the Class View down a little, you can see what I entered as the ui:instanceView property value. It's an HTML template, with instructions for plugging in instance data, that will be output whenever TopBraid sees an instance of this class: It lays out an div element that begins with the address entry's mailing address and then has a small table showing the entry's email address and phone numbers, with these property names bolded in the output. You can take advantage of the full power of SPARQL in these templates, as you'll see in Holger's blog entries, but I kept things simple by mostly just using the spl:object() function to insert specific property values into various places in the HTML. When I view the form tab of the Entry class and click on a row in the Instances view, I see a Resource Form for that instance, like I always did: You can see a new Browser tab next to the Form tab, though, and it lets me see the instance view formatted according to the HTML template that I created in the ui:instanceView value: Even better, TopBraid Live can serve up the data using these HTML templates outside of TopBraid Composer, so that sending a browser to the URLhttp://localhost:8083/tbl/uispin?_resource=http://example.org/addressBook%23Entry_1&_baseURI=http://example.org/addressBook displays the result in the browser (note the use of the base URI to specify the model with the data to display and the escaping of "#" as "%23"): Of course, this HTML can also have links and reference CSS, Javascript, web services, and other applications on the TBL server where it's hosted, so you can build some very sophisticated user interfaces. Check out Holger's blog entries for further ideas on where you can take this, especially when you start incorporating SPARQL queries and their results into the templates.a:Entry_1
rdf:type a:Entry ;
a:city "San Diego" ;
a:email "jerry122@hotmail.com" ;
a:firstName "Jerry" ;
a:homePhone "(738) 610-2019" ;
a:lastName "Snyder" ;
a:mobile "(702) 382-4712" ;
a:postalCode "39248" ;
a:region "CA" ;
a:streetAddress "3137 11th Ave." .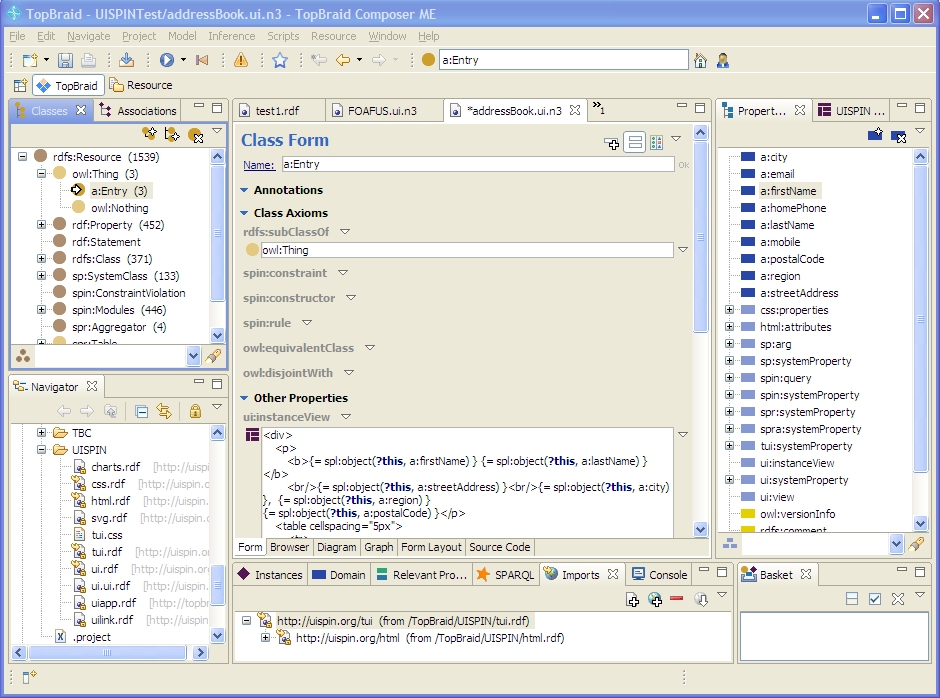
Wednesday, October 27, 2010
TopQuadrant's new Enterprise Vocabulary Manager
The TopBraid platform can be used to build all kinds of applications and solutions. We've recently noticed one particular area where more and more customers needed help, and where semantic technology and our tools were a great fit: the management of multiple connected vocabularies spread out across an enterprise. To meet this need, we've created TopBraid Enterprise Vocabulary Net (EVN), a solution that works out of the box while having all the power of TopBraid Suite behind its customization capabilities. The EVN product page has a long list of its features, which provide everything you need to manage taxonomies and thesaurii (and even create simple ontologies) in multi-user environments. The ability to review proposed changes before rolling them into production, with a choice of reports and other options for analyzing those changes and their potential impact, will be especially useful in larger organizations. The use of EVN requires no knowledge of SKOS, RDF, or the related W3C standards, but the use of these standards behind EVN's graphical user interface is what makes EVN both flexible and scalable. The use of public standards for data, models, and application logic makes it much easier to integrate EVN with other systems than any other vocabulary management solutions we've seen in the marketplace. They also make it easier for EVN to let you set up an environment where different vocabularies in different parts of a large organization can work cooperatively with no need to merge those vocabularies into a single large, central vocabulary. EVN is included in TopBraid Composer Maestro Edition release 3.4, which is now in beta, so you can try it without purchasing a separate product. For a quick overview of the features and what the product looks like, start with thescreenshot tour, or jump right in to the tutorial included with EVN's documentation.![]()
Monday, October 4, 2010
How to: read RSS and RDFa from the web with a SPARQLMotion script
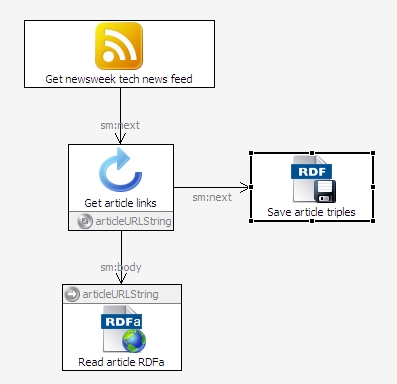
How do you get a SPARQLMotion script to read an RSS or Atom feed as RDF triples? How do you get a SPARQLMotion script to read triples that have been embedded into web pages using RDFa? The answer to both questions is the same: use the specialized SPARQLMotion module for the task. All you have to do is specify the URL of the file with the information you want to read. To demonstrate both, we'll put together a short script that: Reads the RSS feed about technology news from Newsweek magazine Pulls the triples from the RDFa embedded in the Newsweek articles described in the feed Saves the extracted triples in a Turtle file Along with Dublin Core properties such as dc:title and dc:description, RDFa attributes in Newsweek articles store additional RDF metadata using the Open Graph vocabulary developed by Facebook. This makes it easier for Facebook to incorporate additional information about news articles in their applications—for example, if people click the Facebook button next to a Newsweek article in order to share it with their Facebook friends. It also makes it easier for you to use information about these articles in your own applications. The sample application below just saves the retrieved triples in a file, but you could also pass them to other SPARQLMotion modules that could have OpenCalais analyze the text, combine the triples with data from another source, create a new, specialized RSS feed or SPARQL endpoint, or send an email message based on the results of your processing. Retrieving the data is just the beginning. To create this application, start by creating a new SPARQLMotion file called getnewsweektech. (For more detailed background on the steps involved in creating and running a SPARQLMotion script, see the PDF tutorial TopBraid Application Development Quickstart Guide.) Create a new SPARQLMotion script in your getnewsweektech.n3 file. For its first module, select sml:ImportNewsFeed from thesml:ImportFromRemoteModules category and name it GetNewsweekTechNewsFeed. To configure it, you only need to set its sml:url value tohttp://feeds.newsweek.com/newsweek/technology?format=xml, a URL I learned about from Newsweek's web page about their RSS feeds. Once this module pulls down the RSS data and TopBraid converts it to triples, your script will look through these triples for web page URLs provided as RSS link values and then retrieve the triples that are stored as RDFa in those web pages. The script can't pull the triples from all those web pages at once, so we'll use an IterateOverSelect module to drive the next step. We'll specify a SPARQL SELECT query in the IterateOverSelect module to find the RSS link values, and then for each result that this SELECT query finds, another module will retrieve the triples from the web page named by the link value. Drag an Iterate over select module from the Control Flow section of the SPARQLMotion palette and name it GetArticleLinks. Paste the following query in as the value for its sml:selectQuery property: The module that retrieves the RDFa needs a string version of the URL to specify where it should look for the RDFa, so the query above assigns a string version of each rss:item resource's rss:link value to the variable ?articleURLString. The script will execute the body of the IterateOverSelect (a separate module that we haven't created yet) once for each value bound to this variable. You're done configuring this module. Next, we'll create the body of the IterateOverSelect. This can be a series of modules, but for this application we'll only need one. Drag anImport RDFa module from the Import from Remote section of the SPARQLMotion palette and name it ReadArticleRDFa. When configuring this new module, click the white triangle for its sml:url property's context menu and select Add SPARQL expression. This lets you add any combination of SPARQL keywords, symbols, function calls, and operators that returns a single value; for this, all you need here is the variable reference ?articleURLString. Each time this module retrieves triples from the RDFa in the web page at this URL, it will pass along the triples that it found to the next module. If this module has an sml:needsTidy property, set it to True to make it easier to read RSS that isn't well-formed XML. For our script's last module, drag an Export to RDF File module from the palette's Export to Local section and call it SaveArticleTriples. Set its sml:targetFilePath value to newsweekTech.n3; it will write this file to the directory that holds the SPARQLMotion file with your script. Set the module's sml:baseURI to http://example.com/newsweek/tech/metadata or to any URI that you like. All that's left is to connect up the four modules as shown below. When you add a connector out of your Get Article Links Iterate Over Selectmodule, TopBraid Composer will ask you whether your new connector is pointing at the body of the loop (the part to execute for each binding of the selected variable) or at the module that should take control of the script when the iteration is finished. Connect Get Article Links to the Read Article RDFa module with an sm:body link, because that's the part we want executed for each iteration, and connect Get Article Links to Save Article Triples with an sm:next link to transfer control (and the collected triples) there when the iteration is all done. Select the Save Article Triples module and click the green triangle at the top of the workspace to execute the script up to that final module, and you should end up with a newsweekTech.n3 file in the same directory as your getnewsweektech.n3 file that holds the script. This new file will hold triples extracted from the various web pages named in the Newsweek tech news feed. To branch out, you could substitute the names of other Newsweek feeds, or additional ones, and then collect all the triples together. You could drive the whole thing with a TopBraid Ensemble interface where an end user picks the category of Newsweek news (for example, their technology, politics, business, or entertainment categories) whose metadata should be retrieved. You could also find other publications that store RDFa metadata in their articles, or other websites, such as TopQuadrant's. And, as I mentioned earlier, you could combine this with other features of SPARQLMotion and TopBraid to make a very powerful application.PREFIX rss: <http://purl.org/rss/1.0/>
SELECT ?articleURLString
WHERE {
?s a rss:item .
?s rss:link ?articleURL .
LET (?articleURLString := xsd:string(?articleURL)) .
}
Monday, August 16, 2010
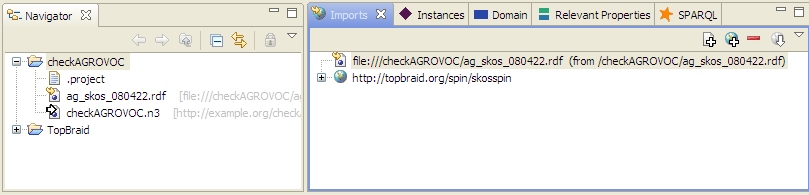
How to: Find SKOS constraint violations in AGROVOC with SPARQL Rules
The W3C makes an OWL ontology for SKOS available, which makes it easier to ensure that your vocabulary conforms to the standard. As a comment near the beginning of it tells us, though, The comment for S13 says that "skos:prefLabel, skos:altLabel and skos:hiddenLabel are pairwise disjoint properties". In plain English, this means that for a given concept, you can't use the same term for any two of these properties. For example, you shouldn't say that "dog" is both the preferred label and the alternate label for a given concept—it should be one or the other. If these constraints are in the ontology as comments and not as something that can be implemented by executable code, how do you find violations of these constraints? The simplest way I've found is to use SPARQL Constraints (with SPIN). We've built on Paul Hermans' work to implement these constraints in the ontology at http://topbraid.org/spin/skosspin. It imports the W3C SKOS ontology and adds one rule to the skos:OrderedCollection class for constraint S36 and rules for the other five constraints to the skos:Concept class. For example, it adds the following three rules for constraint S13: If any of these returns a boolean true, then we know that constraint S13 has been violated. (If you look at the skosspin ontology, you'll see these queries represented as triples, which is more difficult to read but easier to implement than rules expressed as SPARQL queries as shown above. TopBraid Composer can convert between the two formats, and so can a SPARQL Text to SPIN RDF Syntax Converter that Holger Knublauch has made available on the web.) I tested this with the Food and Agriculture Organization of the United Nation's popular AGROVOC thesaurus, a vocabulary "designed to cover the terminology of all subject fields in agriculture, forestry, fisheries, food and related domains", and found over 1600 violations of constraint S13. Because this thesaurus has almost 29,000 concepts and preferred and alternate labels in multiple languages for most concepts, it's easier to violate these constraints than you might think, and I never would have found them without the ability to automate this search. For example, concept http://www.fao.org/aos/agrovoc#c_1135 has an English preferred label of "Buds", 14 preferred labels for other languages such as Farsi and Thai, and 24 alternate labels. Among these, the Slovak skos:prefLabel value and the Sloval skos:altLabel value are both "púèiky", so this concept violates constraint S13. How do we find the violations? I tried it with the free edition of TopBraid Composer, because it has everything you need to define and use SPARQL Rules. (TopBraid Composer Maestro Edition's ability to use these rules from within applications has made it possible for me to add several nice features to applications for some of our clients.) The screenshot below of TopBraid Composer's Navigator and Imports views shows that I created a checkAGROVOC project and added a checkAGROVOC.n3 ontology file to it. This ontology only does two things: it imports the ag_skos_080422.rdf file that I downloaded from the fao.org web site and it imports the skosspin ontology described above for its SPARQL Rules. (It imports a web version of the skosspin ontology and, because of its 62 meg size, the local copy of the actual AGROVOC thesaurus.) With these two files imported, I opened TopBraid Composer's Problems view and clicked that view's "Refresh all problems of current TopBraid file" icon After it finished checking, the Problems view said that there were Warnings and had a plus sign that I expanded to see the first few constraint violations: (You may want to play with the column widths a bit, because the Location column is the one you really want to see.) Double-clicking anywhere on a specific warning line shows the details about that concept on the Resource Form, like this: If you don't see the little yellow warning symbols on the Resource Form that show where the problems are, click the little "Display constraint violation warnings" icon at the top of TopBraid Composer The Problems view above only shows the first 100 of the 2,972 warnings. Clicking the context menu white triangle in the view's upper-right lets you configure Preferences for the view so that you can reset the number of items to be displayed; I had no problem with a figure of 3,000. Now that we know what constraint has been violated, there are other ways to list the concepts that need to be corrected. For example, the following query in TopBraid Composer's SPARQL view lists the identifiers that have the same label for these two properties: Once you execute this query you can export its results to a file and then use that as a reference point to address the issues in the vocabulary. We could have started off by executing this query on the AGROVOC SKOS file, but remember, at the time we didn't know which constraints had been violated. Using SPARQL Rules as extra metadata for class definitions helps to automate the identification of quality issues with the data, letting us use other techniques to focus on the specific problems and how to fix them. Are your SKOS vocabularies violating any of the six extra constraints described in the SKOS specification? As I mentioned, this all works with the free version of TopBraid Composer, which is available for Windows, Mac, and Linux, so you can try it yourself to find out. With the TopBraid Composer Maestro edition, you can build applications for end users who can then maintain these vocabularies with a web-based interface instead of using TopBraid Composer. The user interface for notification of constraint violations then becomes one of the many things you can customize to the needs of your end users. You can also define new constraints around your own shop's business rules—for example, to require that all labels begin with an upper-case letter—and you can set TopBraid Composer or your application to highlight these violations as soon as they occur, instead of checking in batch mode like I did above. To summarize, what we've seen here is really just a starting point, and there are all kinds of places where you can take it to improve the consistency and value of your vocabularies.The Simple Knowledge Organization System (SKOS) vocabulary management specification is gaining popularity because, as a standard, it makes it easier to share taxonomies and thesaurii between different systems. It also guards investments in vocabulary development against the potential problems of dependence on a proprietary vendor format.
A number of semantic conditions are *not* expressed formally in this schema. These are:
S12
S13
S14
S27
S36
S46
For the conditions listed above, rdfs:comments are used to indicate the conditions.# Constraint S13: skos:prefLabel, skos:altLabel and skos:hiddenLabel
# are pairwise disjoint properties.
ASK WHERE {
?this skos:prefLabel ?label .
?this skos:altLabel ?label .
}
ASK WHERE {
?this skos:prefLabel ?label .
?this skos:hiddenLabel ?label .
}
ASK WHERE {
?this skos:hiddenLabel ?label .
?this skos:altLabel ?label .
}
 . A "Progress Information" message box told me that TopBraid Composer was "Checking SPIN constraints on skos:Concept", which took a few minutes because there were plenty to check.
. A "Progress Information" message box told me that TopBraid Composer was "Checking SPIN constraints on skos:Concept", which took a few minutes because there were plenty to check.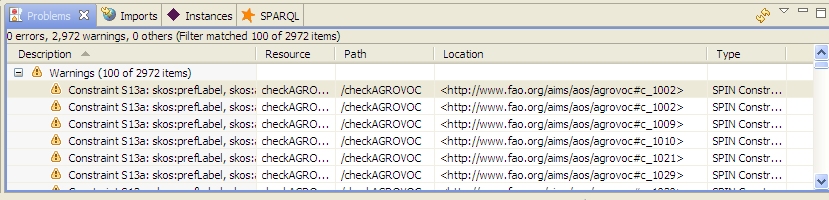
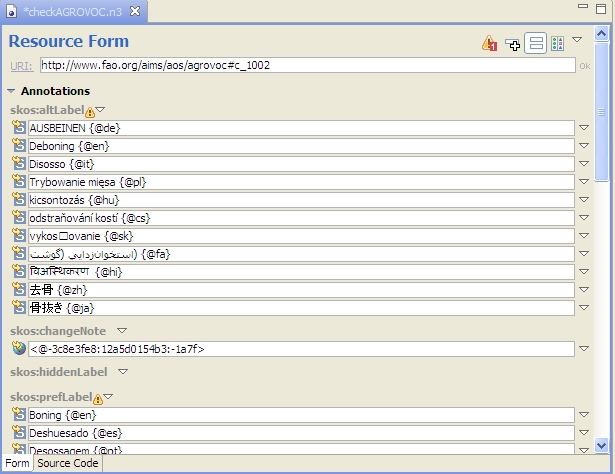
 . In this case, a bit of scrolling down when viewing concept c_1002 shows that the same term appears as both Hungarian skos:altLabel and skos:prefLabel property values for this concept.
. In this case, a bit of scrolling down when viewing concept c_1002 shows that the same term appears as both Hungarian skos:altLabel and skos:prefLabel property values for this concept.SELECT ?s ?label
WHERE {
?s skos:prefLabel ?label .
?s skos:altLabel ?label .
}
Tuesday, July 27, 2010
How to: use the SPARQLMotion debugger
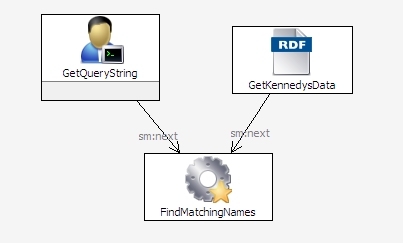
Since release 3.3, TopBraid Composer has included an interactive debugger for SPARQLMotion scripts that can make your development go much faster. TopQuadrant VP of Product Development Holger Knublauch wrote a nice overview of the debugger's features in his blog; below is a short hands-on tutorial in the use of the debugger. We're going to put together a short SPARQLMotion script with a problem that prevents it from running properly. Experienced SPARQLMotion developers may notice the problem when we add it, but leave it in there—we'll see how the SPARQLMotion debugger helps us locate it. Our script will prompt the user for a string to search for and then list the first and last names of everyone in the sample kennedy data file included with TopBraid Composer who has that string as part of their first name. First, create a new SPARQLMotion file and give it a base URI of http://www.topquadrant.com/debugdemo and a file name of debugdemo. (For a more detailed description of how to create a SPARQLMotion file, see the "Creating and running a SPARQLMotion script" chapter of the TopBraid Application Development Quickstart Guide.) Once your new file is open, create the script by selecting Create SPARQLMotion Script from the TopBraid Composer Scripts menu, and for its initial module type select sml:EnterLiteral. This is the module that will ask the user to enter a query string, and you'll find it under sml:ImportModules -> sml:ImportFromVariousModules. For the name of your new module instance, enter GetQueryString. Click the OK button and you'll see your script on the SPARQLMotion workspace with its one module. Double-click the GetQueryString module icon and enter queryString as the sm:outputVariable value and Enter query string as the sml:text value. When the script runs, this module will display a message box that prompts the user with this message. After the user enters a value into the field on that message box, the value will be stored in the variable queryString for use by later modules in the script. You are now done configuring this module. There are two more modules to add. Drag an Import RDF From Workspace module from the Import from Local section of the SPARQLMotion palette onto your workspace and name it GetKennedysData. Double-click it to configure it, and set the sml:sourceFilePath value to /TopBraid/Examples/kennedys.rdf. For the third and final module, drag an Apply Construct module from the RDF Processing section of the Palette and name it FindMatchingNames. Set its sml:replace value to true so that the module passes along only the triples that it creates. Set its sml:constructQuery property to the following query: (Instead of setting the prefix for the kennedys data at the beginning of this query, you could also do it on the script file's Ontology Overview screen.) This query passes along the firstName and lastName triples for anyone in the data file who has the value of the searchString as part of their firstName value. (The "i" provided as the third parameter to the regex() function tells it to do a case-insensitive comparison.) Connect up the three modules so that the script look like this: To test the script, select the FindMatchingNames module and click the green arrow at the top of your workspace to run all the modules up to the selected one. When the GetQueryString module displays a message box asking you for a query string value, enter Carol.When the script finishes running and you see the SPARQLMotion Script Executed message box, make sure that the Display result triples checkbox is checked before continuing so that you can see what data the script found. Although the kennedys data includes a Caroline and a Carolyn, you won't see any triples in the SPARQLMotion Results view when the script is finished running. Let's use the debugger to find out why. The small blue circle icon at the top of your SPARQLMotion workspace Click the green arrow to run the script again, enter "Carol" as the query string. When the script reaches the module with the breakpoint, it displays the debugger window: The left part of the window has the Execution Plan, which lists the modules in the order that they will be executed, with a check mark next to each module that's been set as a break point. As you debug, you're free to check and uncheck any of these. The bottom of the window displays the arguments to the module and their values, and the top shows three tabs: Variables, Query, and Input Graph. Let's start with the last tab: click Input Graph. On the tab's Input Graph panel, click the plus sign, and you'll see the that kennedys data is definitely being provided as input to the FindMatchingNames module. Click that line, as shown below, and you'll see some of its data appear in the lower panel. Scrolling down there shows that CarolineKennedy and CarolynBessette are in the data being passed along, so we can't blame our script's retrieval of data for its inability to show the expected results. Now select the debugger window's Query tab. This lets you execute test queries on the data passed to the module. Because FindMatchingNames is an Apply Construct module, the default query shown on the Query tab is a SELECT version of the CONSTRUCT query that you entered when you created this module. You can enter any SELECT query you want in in this panel of the debugger window and run it without affecting the state of the running script. Commenting and uncommenting lines of this query and then re-running it is a particularly valuable technique for exploring what information is available to your SPARQLMotion script at this point in its execution and what your application logic has done with that data. Perhaps the problem is in the query's FILTER expression. Add a pound sign at the beginning of that line to comment it out, and click the green triangle in the upper-right to run the SELECT query shown in the debugger window. You'll see plenty of s, first, and last values appear in the lower panel, including Caroline Kennedy and Carolyn Bessette, so it looks like a problem in the FILTER expression prevented the query from passing along the requested data. The ?first variable is clearly being set properly, because we saw plenty of output when we commented out this line, so maybe the problem is with the ?searchString variable referenced in the FILTER line's regex() function call. Click the debugger window's Variables tab to display it, and you'll see the problem: the GetQueryString module stored the entered value in a variable called queryString, and the query's FILTER expression was checking values against a non-existent searchString variable. (In a real debugging session, the Variables tab is probably the first one you'd check, which is why it displays first.) Go back to the Query tab, uncomment the FILTER line, change ?searchString to ?queryString, and click the green arrow. You should now see Caroline Kennedy and Carolyn Bessette and no one else show up under the query in lower part of the debugger window. At this point, you've only fixed the debugger window's temporary query used to explore the workings of the script, and the application itself still needs to be fixed. Click theContinue button to resume execution of the script past the breakpoint. If there were more modules and any of them were set as break points, the Continue button would stop at each one and display the debugger window, but your script has no more breakpoints. (If there were more modules after FindMatchingNames module, the Step Into button would execute them one at a time so that you could review the three debugger tabs for information about those modules as they executed.) Once the script completes, change ?searchString to ?queryString in the FindMatchingNames module's query, click the debugger breakpoint icon while the FindMatchingNames icon is selected to turn off its breakpoint indicator, and run the query again with the same "Carol" input string. It should run with the expected results appearing in theSPARQLMotion Results view. Although we ran this SPARQLMotion script from within the SPARQLMotion editor, you can still set breakpoints and check all the same information about a SPARQLMotion script that is invoked from somewhere else—for example, from a TopBraid Ensemble Application or a from web service. (This assumes that the script is running under the TopBraid Live Personal Edition Server included with the TopBraid Composer Maestro Edition, which you use to develop these scripts.) This makes the debugger invaluable for just about all kinds of TopBraid development, and you'll find more uses for it as you use it more. Again, review Holger's blog posting for additional ideas.Creating our script
PREFIX k: <http://topbraid.org/examples/kennedys#>
CONSTRUCT {
?s k:firstName ?first .
?s k:lastName ?last .
} WHERE {
?s k:firstName ?first .
?s k:lastName ?last .
FILTER regex(?first, ?searchString, "i") .
} 
Using the debugger
 toggles whether the selected icon is a debug breakpoint. On the SPARQLMotion workspace, make sure that your FindMatchingNames module is selected and then click that small blue circle. This will add a blue circle to the module icon to indicate that it is now a breakpoint. You can set as many modules you like as breakpoints, but for this exercise we'll just set this one.
toggles whether the selected icon is a debug breakpoint. On the SPARQLMotion workspace, make sure that your FindMatchingNames module is selected and then click that small blue circle. This will add a blue circle to the module icon to indicate that it is now a breakpoint. You can set as many modules you like as breakpoints, but for this exercise we'll just set this one.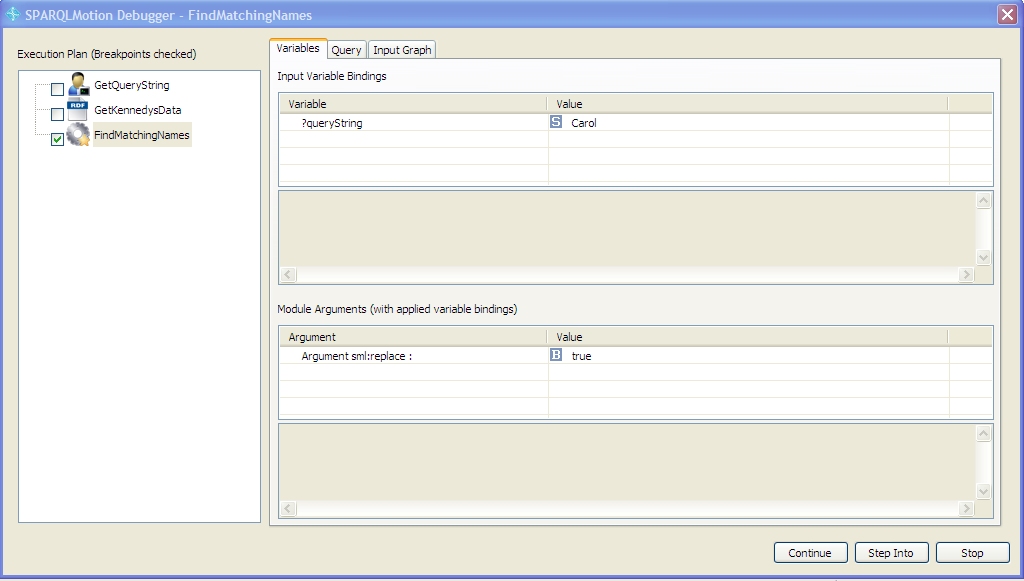

Debugging your own applications
Friday, May 7, 2010
How to: Publish your Linked Data with TopBraid Live SPARQL Endpoints
A SPARQL Endpoint service implementation is packaged with TopBraid Live and is available out-of-the box for both TopBraid Live Personal Server (TopBraid Composer-ME running on localhost:8083), and TopBraid Live Enterprise Server (for more information, see TBL Home page). Creating a SPARQL Endpoint for your data is therefore an easy three-step process:
- Load the model you wish to query into your TBL/TBC-ME workspace.
- Use the GRAPH SPARQL keyword to access any named graph in the workspace.
- Send a SPARQL query in the query string of a url that access the TBL SPARQL endpoint.
For example, if you have TBC-ME running, the TopBraid Live Personal Server is automatically available. Open a browser window and enter the following URL:
http://localhost:8083/tbl/sparql?query=SELECT DISTINCT ?p WHERE {GRAPH <http://topbraid.org/countries> {?s ?p ?o} }
This URL passes a query string that is applied to the specified graph, the countries.owl example included in the TopBraid library. The query is passed to TopBraid Live and executed using TBL's SPARQL engine. The results are converted to the SPARQL Endpoint format and returned via HTTP. The above URL specifies the TBL Personal Server (via TBC-ME's localhost:8083) as the endpoint. If you have TopBraid Live Enterprise Edition running on a server, just substitute the server address for your Enterprise server.
To further explore the ease of creating SPARQL Endpoints with TopBraid Live,
click here to access a page that defines an HTML form that submits a query to the TBL Personal Server SPARQL Endpoint. Copy and paste the following queries that use some of the example models included in the TopBraid library.
This query finds all countries and their abbreviations from the countries model in TopBraid/Examples:
# Get all countries and abbreviations from countries model
PREFIX countries: <http://topbraid.org/countries#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT ?name ?abbrev
WHERE
{ GRAPH <http://topbraid.org/countries>
{ ?country a countries:Country .
?country rdfs:label ?name .
?country countries:abbreviation ?abbrev .
}
}
This query finds all children of Joseph Kennedy from the kennedys model in TopBraid/Examples:
# Find Joe Kennedy's children in kennedys model
PREFIX k: <http://topbraid.org/examples/kennedys#>
SELECT ?cname
WHERE
{ GRAPH <http://topbraid.org/examples/kennedys>
{ k:JosephKennedy k:child ?child .
?child k:name ?cname .
}
}
Again, substitute your Live server address for "localhost:8083" in the action tag of the HTML file to apply queries to your Live server.
Using SPIN functions in SPARQL Endpoints
TopBraid SPARQLMotion Functions and user-defined SPIN functions registered in a Live workspace can also be used in SPARQL Endpoint queries. For example, the following query uses the TopBraid SPARQLMotion Function smf:if() to compute the age of all persons at death or their current age using the example kennedys model. Instead of returning variable bindings via SELECT, this query returns a RDF graph via CONSTRUCT. Since the graph is in RDF/XML format, the file returned by the endpoint can easily be imported into existing RDF/OWL models.
# infer age at death or age as of 2010
PREFIX k: <http://topbraid.org/examples/kennedys#>
PREFIX smf: <http://topbraid.org/sparqlmotionfunctions#>
CONSTRUCT {?person k:age ?age}
WHERE
{ GRAPH <http://topbraid.org/examples/kennedys>
{ ?person k:birthYear ?byear .
OPTIONAL {?person k:deathYear ?dyear}
LET (?age := smf:if(bound(?dyear), ?dyear-?byear, 2010-?byear))
}
}
Note that the age computation is hardcoded for 2010. A SPARQL query that returns the current year can be defined with a few statements. An example is shown in the kennedysSPIN model in the TopBraid Library, see TopBraid/Examples/kennedysSPIN.rdf in the Composer workspace. If you look at the SPIN function getCurrentYear (defined as a subclass of spin:Functions, which is a subclass of spin:Modules), it finds the current year as the first four characters returned in xsd:dateTime format returned from the function afn:now().
Instead of copying this code into the query, let's register this as a SPIN function so it can be called by any model in the workspace, including SPARQL Endpoints. Do the following:
- Re-name the file kennedysSPIN.rdf to kennedysSPIN.spin.rdf. Adding the .spin extension registers all of the SPIN functions in this model with the workspace, allowing SPIN functions to be called without importing or opening the files.
- From the TBC-ME menu, select Scripts > Refresh/Display SPARQLMotion functions... This will register the functions for the current session. When Live or Composer is started, the system will scan the files in the workspace for .spin files and register all functions. The extra step is needed here only if the file name was changed without stopping the Composer session. A Deploy (Export... Deploy in Composer) to a Live server will automatically refresh scripts.
Now try the same query with the following changes:
# infer age at death or age from current year
PREFIX k: <http://topbraid.org/examples/kennedys#>
PREFIX smf: <http://topbraid.org/sparqlmotionfunctions#>
PREFIX kspin: <http://topbraid.org/examples/kennedysSPIN#>
CONSTRUCT {?person k:age ?age}
WHERE
{ GRAPH <http://topbraid.org/examples/kennedys>
{ ?person k:birthYear ?byear .
OPTIONAL {?person k:deathYear ?dyear}
LET (?age := smf:if(bound(?dyear), ?dyear-?byear, kspin:getCurrentYear()-?byear))
}
}
Note the use of the user-defined SPIN function getCurrentYear(). This feature can be used to call any SPIN function including those that are defined by SPARQLMotion scripts. This raises the potential of using SPARQL endpoints for a wide range of processing capabilities, including importing models from outside of a Live workspace, processing triples before querying, applying queries to inference results, integrating models from different file types, and other kinds of SPARQL and RDFS/OWL processing. For example, a SPARQL Endpoint request could call a SPARQLMotion script that runs standard RDFS or OWL inferences before submitting the query, thus returning results from both inferred and asserted triples.
Advanced SPARQL Protocol: Federated SPARQL Queries
The SPARQL SERVICE keyword sends a query to remote service endpoint. Since TopBraid Live supports the SERVICE keyword, SPARQL endpoint queries to TopBraid Live can call other SPARQL Endpoints! Try the following query in the example query form.
PREFIX k: <http://topbraid.org/examples/kennedys#>
PREFIX smf: <http://topbraid.org/sparqlmotionfunctions#>
CONSTRUCT {?child k:birthDate ?birthdate}
WHERE
{ GRAPH <http://topbraid.org/examples/kennedys>
{ k:RoseFitzgerald k:child ?child .
?child k:firstName ?fname .
?child k:lastName ?lname .
?child k:gender k:female .
?child k:spouse ?spouse .
?spouse k:lastName ?slname .
LET (?dbpRsc := smf:buildURI("http://dbpedia.org/resource/{?fname}_{?lname}_{?slname}"))
SERVICE <http://dbpedia.org/sparql>
{ ?dbpRsc <http://dbpedia.org/ontology/Person/birthDate> ?birthdate .
} .
}
}
This query is applied to the kennedys example model to query for female children of Rose Fitzgerald and sends a query to the DBPedia SPARQL Endpoint to find their birth dates. The buildURI() function will generate a URI that is known in DBPedia, such as <http://dbpedia.org/resource/Eunice_Kennedy_Shriver>. The results from DBPedia bind the birth date to ?birthdate, which is returned in the TopBraid Live SPARQL endpoint response. As long as DBPedia is up and running, the result federates data from two SPARQL Endpoints, realizing the potential of linked data sources.
Conclusions
SPARQL endpoints are a complement to TopBraid Live's ability to create
RESTful Web services. While Web services are more flexible, allowing data to be returned in any text-based format, SPARQL endpoints can be used in a variety of applications expecting SPARQL result sets in an XML format. TopBraid Live significantly improves on existing SPARQL Endpoints with capabilities to federate queries and design functions and scripts that process data for external usage.
These examples demonstrate the power of TopBraid Live as an RDF back-end. Using a straightforward HTML form, one can access to full power of TopBraid Live and advanced SPARQL queries. These examples can be directly applied against the Personal Server version of TopBraid Live, packaged in TopBraid Composer-Maestro Edition (TBC-ME), which is freely available for a 30-day trial. TopBraid Live Enterprise Edition is deployed as a Tomcat servlet for Web-enabled access. For more information, see the TopBraid Live web page.
Sunday, April 18, 2010
TopBraid release 3.3: three things that have already made my application development easier
TopBraid Suite Release 3.3 has many features that let you add new things to the semantic web applications that you develop. As I've worked lately on some client application development, three new features in particular have made this work go more quickly and easily.
SPARQLMotion debugger
The SPARQLMotion debugger lets you set breakpoints and examine variables like any other debugger. It also lets you enter SPARQL queries against the data available to the SPARQLMotion module where you set the breakpoint, a feature that has made it much easier for me to understand why a certain module was doing what it was doing instead of what I thought it would be doing. A future entry in this blog will describe the SPARQLMotion debugger in more detail; for now you can get a nice tour from Holger Knublauch's introduction to it.
Base URI Management
Applications typically read and write files, but I sometimes forget that in semantic web application development, the real identifier for a resource such as a file is not its filename, but a URI. After all, you can have several files with the same name in different folders or directories, so a URI should provide a truly unique identifier. If you somehow have the same URI representing more than one file (for example, if you made an alternative copy of your application development folders and used both in the same workspace), this can lead to trouble.
Release 3.3's new "Base URI Management" screen for both the Enterprise Server and Personal Server editions of TopBraid Live lists the URIs of the files and other data resources being tracked in each project and puts a warning icon next to any URI being used for more than one resource. Once you straighten these out by assigning a new base URI to one of the files (or, more likely, by deleting an old file that you had forgotten was there) you'll have much better control over the use of those resources.
Application Event Dashboard
I recently needed to use TopBraid Ensemble's drag and drop capability for an application I was working on. I had never used it before, but instead of pesteringing co-workers to show me an example of drag and drop in action, I opened up the Default TBE application with the kennedys.owl data model, clicked the wrench icon to display the Application Configuration screen, and went to the new Event Wiring screen of the Application Configuration dialog box. After clicking its Display All button, in the top list I saw that for this application the Graph Editor and Query components had Drop listener events defined, and in the bottom list I saw that the Grid and Tree components had Dragging post events defined, so I knew I could drag from a Grid or Tree component to the Graph Editor and Query components in this TBE application. I tried dragging a few resources between these components, and it worked; then I could examine how this was configured and reproduce it in my own application.
It's only been a few weeks since release 3.3 has been out, so I'm sure I'll be growing to appreciate other new features more in the coming months.
Tuesday, April 6, 2010
What's new in TopBraid Suite 3.3
The new 3.3 release of the TopBraid Suite includes significant improvements to TopBraid Composer, TopBraid Ensemble, and TopBraid Live. For more details on the new features, see the Release Notes and detailed change list.
TopBraid Composer
Release 3.2 let you could run a SPARQLMotion script up to a certain point and then examine the triples that it would have passed along, which was handy for debugging. Release 3.3 brings a real SPARQLMotion debugger, which lets you examine all kinds of useful information at the script breakpoint: variable bindings, the arguments passed to the current module, the result of test queries entered at the break point, and the engine's execution plan. This will make development of more sophisticated SPARQLMotion scripts much easier.
More automated handling of taxonomies and other controlled vocabularies stored using the SKOS standard.
Improved OWL 2 support.
The introduction of UISPIN, a SPARQL-based framework for describing user interfaces. Just as SPIN let you define business rules and application logic, UISPIN lets you describe an application's visual presentation, all with RDF and standard SPARQL underneath, and TopBraid 3.3 lets you see that definition in action. A recent blog posting by Holger Knublauch describes a sample application.
For customers with complex policies on the use of open source software, the new TBC Clear and TBC-ME Clear versions of TopBraid Composer come with open source components (outside of Eclipse and Jena) unbundled, letting you select the components to add back in according to your needs and policies.
TopBraid Ensemble
The new Application Event Dashboard makes it much easier to track which events are used by which form components.
Release 3.3 gives you greater control over form appearance. You can hide component tabs and resizing dividers, and new components make it easier to add white space and formatted text.
The form component's "Edit Mode" lets TopBraid Ensemble application developers offer their end users new options in how they edit data in forms.
When SPARQLMotion scripts triggered from TopBraid Ensemble generate HTML documents, they can be displayed in the browser automatically.
When someone is using an Ensemble application, the displayed URL can be used to record and reproduce the state of the application at that point.
A new Flex Developer's Guide shows how to make your own components to incorporate into your TopBraid Ensemble applications.
The new Basket component works like TopBraid Composer's Basket view, serving as a "scratch pad" for resources.
TopBraid Live
Release 3.3 of TopBraid Live gives server administrators greater control over running sessions and the relationship of file resources to the URIs used to identify with them. URI conflicts and missing imports are easier to identify and resolve, and multiuser change propagation and file indexes are also easier to manage from the Server Administration Console.
SPARQLMotion
The SPARQLMotion debugger mentioned above is built into TopBraid Composer. You can execute SPARQLMotion scripts to drive the execution of application logic on a TopBraid Live server from both TopBraid Composer and from TopBraid Ensemble, so improvements to SPARQLMotion capabilities benefit the entire TopBraid Suite. Release 3.3 makes several new things possible with SPARQLMotion scripts:
A spellchecker accepts blocks of text and returns triples that identify words not found in its configurable dictionary, along with suggested corrections.
For added flexibility in the use of SPARQLMotion modules, arguments passed to them can now be SPARQL expressions, SELECT queries, or SPIN templates.
New SPIN functions let you build unique URIs and compute AVG, MIN, MAX aggregations and more from the SPARQL queries in your scripts.
The cache-all option speeds the use of queries against disk-based databases.
Considering that it's a minor upgrade, there are a lot of new toys to play with!
Sunday, March 21, 2010
How to: deploy your TopBraid applications on a TopBraid Live Enterprise server
An updated version of this blog post is now available as a chapter in the TopBraid Application Development Quickstart Guide (pdf).
So far, as we've learned how to create a TopBraid Ensemble application, how to create and run a semantic web service, and how to call a SPARQLMotion script from TopBraid Ensemble, we've always used the TopBraid Live (TBL) Personal Server that's built into TopBraid Composer (TBC) to test our applications. However, the reason developers create these applications on TBC is for others to use, and that's where the TBL Enterprise Server (purchased separately from TBC) comes in.
When you deploy your TopBraid applications on a Enterprise TBL Server, many users can use your applications simultaneously, and none of them need a copy of TopBraid Composer. In this posting, we'll see how simple it is to copy your applications to a TBL Enterprise Server where you end users have access to them. (And remember, those "end users" aren't always people; when you deploy a semantic web service to a TBL Enterprise Server, it can be a first-class member of any number of Service-Oriented Architecture applications, serving as a building block for larger applications by fulfilling requests from automated processes elsewhere in the architecture.)
Referencing your server
In the following example, I'm going to deploy an application to a TBL Enterprise Server running on my local machine and configured as a Tomcat servlet listening to port 8080, making the URL of the server http://localhost:8080/tbl/tbl. If the Enterprise Server was installed on a host named www.domain.com and used the same port, the URL would be http://www.domain.com:8080/tbl/tbl, so you would follow the same steps, substituting that name.
Deploying apps to the server
If you package all the files needed to run an application in a single project, which is a root file in TBC's Navigator view, it's a convenient way to upload a collection of related files to the TBL Enterprise Server. So, for example, if the personScripts.sms.n3 file that you created in the last posting is not in its own project, create one called personProject and move it there.
Right-click on the project folder icon in TBC's Navigator view and pick Export. On the Export dialog box, select "Deploy Project to TopBraid Live Server" from the TopBraid Composer section of the menu and click the Next button.
On the Deploy Project to TopBraid Live Server dialog box that appears, enter the URL of the server where you want to send your app (for example, http://localhost:8080/tbl/tbl, as described above) in the Server URL field. The remaining fields are self-explanatory: enter a user name and password if the server was set up to require it (always a good idea for serious production applications) and check "Overwrite existing project with the same name" if there is any chance that a project with that name already exists.
Click the Finish button, and TBC will show you upload progress and then let you know it's finished:

If you sent a project with the personScripts.sms.n3 file created in the How to: call a SPARQLMotion script from TopBraid Ensemble posting to the Enterprise server, and a different computer can access that one as http://www.domain.com:8080/tbl/tbl/ or http://192.168.1.2:8080/tbl/tbl/, then sending a browser on the other computer to one of these URLs will display the TopBraid Suite Console screen. On that computer you can then follow all the steps described in that posting's "Testing It" section, even though you're doing it remotely, right up through the use of the "Age at Death" menu choice that you implemented.
You can upload a web service to the Enterprise TBL server the same way. For example, in How to: create and run a semantic web service we saw that after defining a web service in the file ws1.sms.n3 and registering the function that invokes the service by selecting "Refresh/Display SPARQLMotion functions" from the TBC Script menu, you could test this web service by entering the following URL in a browser:
http://localhost:8083/tbl/actions?action=sparqlmotion&id=searchKennedys&arg1=Rob
This sent the request to the TBL Personal Server included with TBC. To deploy the web service on the Enterprise Server, upload the project that holds the ws1.sms.n3 file file as described above. Then, if the server is running on the local machine and listening to port 8080, you can test it with the following URL:
http://localhost:8080/tbl/tbl/actions?action=sparqlmotion&id=searchKennedys&arg1=Rob
To call this web service from another computer on the same network (which could be another one on your intranet, or could be a computer on the public internet if the machine running the TBL Enterprise Server is accessible there), substitute the appropriate computer name or IP address for "localhost" in that URL.
Installing TopBraid Ensemble Apps on the Enterprise Server
As we've seen in an earlier posting, when you create a TopBraid Ensemble (TBE) application, you save your screen layout with the Save App button. After clicking this button, the Save To field on the Save Application As dialog box shows server.topbraidlive.org as the default project in which to save the application, but you can select another one. (You can't create a new project from within TBE, so if you want to save the application in a particular project, make sure you've already created that project you need in TBC's Navigator view.)
If you named your TBE application MyTBEApp and saved it in the project MyTBEProj, in TBC's Navigator view you'll see that it stored MyTBEApp.n3 in a subdirectory of MyTBEProj named user-applications. Once you upload the MyTBEProj project to the TBL Enterprise Server the same way you uploaded the other projects described above, you'll see MyTBEApp listed on the right side of TopBraid Live's TopBraid Suite Console screen at http://localhost:8080/tbl/tbl/ under the column heading "Applications Under Development":

When you click the application name on the TopBraidSuite Console, if it wasn't saved with a particular set of data, it will prompt you to pick one. Once you see the application screen you designed, your browser's navigation toolbar will show the URL that you would use to send users directly to that application once you substituted the computer name for "localhost" as described above. It will be a long URL, so instead of actually giving that URL to your users, you'd be more likely to use it as the href value of a link on a web page that takes them to the application.
TopBraid Composer puts a lot of capabilities at your fingertips. When you copy the web services, TBE applications, and any SPARQLMotion scripts called by those TBE applications from TBC to a TBL Enterprise Server, you can make the power of your semantic web applications available to a wide range of people and applications throughout your enterprise or even throughout the World Wide Web. That's a lot of power.
Friday, March 5, 2010
How to: call a SPARQLMotion script from TopBraid Ensemble
An updated version of this blog post is now available as a chapter in the TopBraid Application Development Quickstart Guide (pdf).
In earlier entries, we've seen how to create a TopBraid Ensemble application and how to create and run a semantic web service. When you combine these, the user interface that you create with TopBraid Ensemble (TBE) can take advantage of all the power of SPARQLMotion scripts, which can accept parameters from a TBE app, run in the background, and pass the results back to be incorporated into the TBE user interface.
In this posting, we'll see how to add an "Age at death" choice to the TBE gear menu, which triggers SPARQLMotion scripts. When your end user selects a person in the kennedy data and picks this menu choice, a SPARQLMotion script will return either a message about the person's age at death (assuming that they've already had their birthday in the year of their death) or the phrase "Still alive" for display in TBE.
Defining the function to call
As we saw in the posting on creating web services, the first step is to define a SPIN function that points to a SPARQLMotion script, and then we create the script. (The following description assumes that you've read the more detailed description of the same steps in How to: create and run a semantic web service.) Start by creating a new SPARQLMotion file called personScripts, and remember to check "Script will declare (Web) Services or Functions (.sms extension)" on the Create SPARQLMotion File dialog box.
Next, in the Classes view, create a subclass of spin:Functions called AgeAtDeath. The rdfs:label value for this function is important, because that's the text that will appear on the TBE gear menu; drag this property from the Properties view onto the class form for your new function and enter "Age at death" there.
The next step is to use the function's spin:constraint property to identify the argument being passed to the function. For our new application, we want the argument to be the identifier for the currently selected member of the Kennedy family in the TBE application—or, in TBE development terms, the URI for the selected resource—so that the function knows whose age at death to calculate. To make the selected resource the argument, on the AgeAtDeath class form click the spin:constraint property's white triangle context menu and pick "Create from SPIN template". On the Create from SPIN template dialog box, pick sml:SelectedResourceArgument from the selection of "Available Ask/Construct Templates". Click the plus sign next to the predicate field and pick sml:selectedResource. You're now finished specifying the spin:constraint.
Remember, a SPIN function identifies the SPARQLMotion script to call by naming the script's last module in the function's sm:returnModule property. The module that we need to point to doesn't exist yet, so pick "Create and add..." from this property's context menu, and then pick sml:ReturnText from the sml:ExportToRemoteModules section of the sml:ExportModules choices and name your new module ReturnComputedAge. It's exporting to a remote module because a script on the server is returning the value to a calling process on the client, and when a TBE application gets text passed by a Return Text module, it displays that text in a message box, which is what we want for this application.
Creating the SPARQLMotion script
You don't need to create a new SPARQLMotion script, because when you defined the sml:selectedResource and sm:returnModule modules as part of the AgeAtDeath function, TopBraid Composer put them into a new script for you. Select "Edit SPARQLMotion Script" from the Scripts menu, and you'll see see this script with icons representing these two modules waiting for you to add new modules and connect them up.
Drag the Selected Resource icon to the top of the screen, because it will be the beginning of your script. Under it, create a new module to perform the query that will compute the age at death of the selected resource by dragging a Bind by select icon from the Control Flow section of the SPARQLMotion workspace palette onto the workspace. Name this module ComputeAge and set its sml:selectQuery property to the following SPARQL query:
PREFIX k: <http://topbraid.org/examples/kennedys#>
SELECT ?deathAge
WHERE {
?selectedResource k:birthYear ?birthYear .
OPTIONAL {
?selectedResource k:deathYear ?deathYear .
} .
LET (?deathAge := smf:if(bound(?deathYear),
(?deathYear - ?birthYear),
"Still alive")) .
}
It uses the SPARQLMotion extension function sml:if to calculate and return the person's age at death if the ?deathYear variable is bound and to return the string "Still alive" if it's not bound.
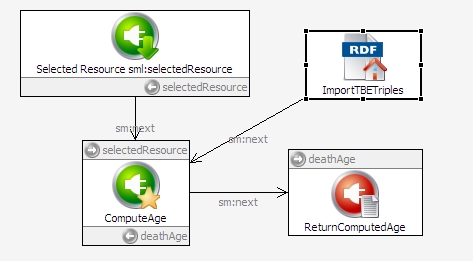
The sml:selectQuery property is the only one to set for this module, so you're ready to add a connection from the Selected Resource module icon to the ComputeAge one.
The ComputeAge module knows what SPARQL query to execute, but it doesn't know what data to execute it with. Drag an Import current RDF module, which passes all of the triples of the currently open model to the script, from the Import from Various section of the palette to the workspace. Name it ImportTBETriples and add a connection from this module to the ComputeAge one. You don't need to set any of its properties; it will know what to do.
The query above binds the computed answer to the variable ?deathAge. This is what we want to return to the TBE application that calls the AgeAtDeath function, so set the sml:text property of the returnComputedAge module that's been waiting for you to use it to {?deathAge} and connect the ComputeAge module icon to the returnComputedAge one. Your completed script should look like this:
The gear menu in TBE won't know about the AgeAtDeath function until you register it with the server, so select "Refresh/Display SPARQLMotion functions..." from from the TopBraid Composer Script menu, and after a few seconds you'll see the updated list of registered functions on the Console view.
Testing it
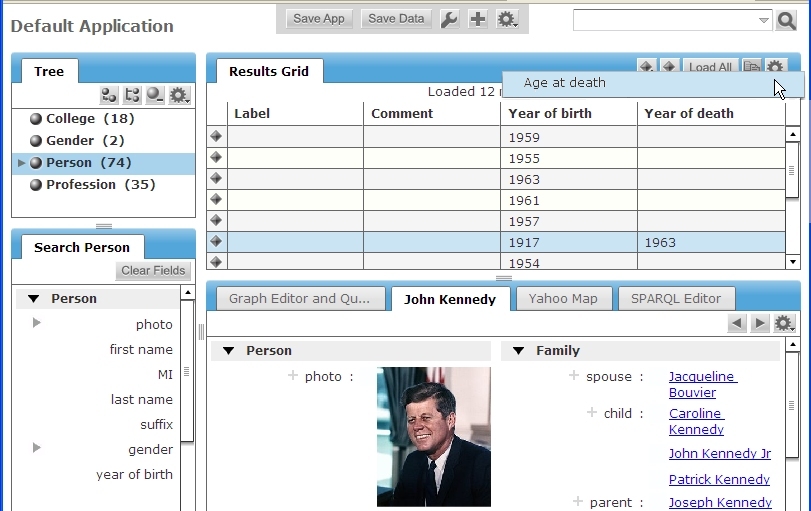
From the TBL main screen, pick "Default Application (configurable)," and on the "TopBraid Live Data Selection" screen pick kennedys from the "Data from Project TopBraid" section. When the application appears, click Person in the Tree component in the upper-left to list data about members of the Person class on the Results Grid. Once they appear there, click a row that includes both a "Year of birth" and a "Year of death" value to select it.
Click the gear menu in the upper-right, and you should see your new "Age at death" menu choice:
Select it, and you'll see a message box showing the result of the calculation from the SPARQLMotion script:
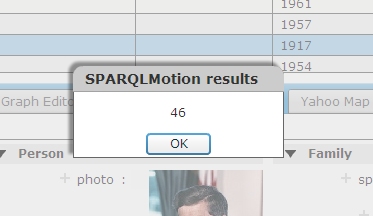
Try again with a row of the Results Grid that has a "Year of birth" but no "Year of death" value, and you should see a similar message box appear with the "Still alive" message.
Taking it further
If you created ten different applications like this, the menu choices for all ten would appear on all gear menus in all of your TBE applications. To limit the menu choice to only appear on the gear menu for applications showing instances of a particular class, such as members of the Person class from the kennedys data, you can name that class in the ValueType property of the sml:SelectedResourceArgument when you configure the constraint in the function you're defining.
The SPARQL query used in your SPARQLMotion script set the return value of ?deathAge to a very simple value: either (?deathYear - ?birthYear) or the string "Still alive". Browse through the "TopBraid SPARQLMotion Functions Library" help panel and you'll see an extensive choice of functions that you can use to assemble a much more complex string to return, with substring and case manipulation functions, regular expression matching, concatenation functions to assemble multiple pieces together, and more.
This SPARQLMotion script also had very limited input: the URI of the resource to query about and the data from the kennedys file. As we've seen in other postings, a SPARQLMotion script can open up many other kinds of both local and remote data, so the URI passed from TBE can be used in much more sophisticated kinds of processing. And, as we saw in How to: create a TopBraid Ensemble application, you can custom-design your own TBE screens to be the front end of your application. It's a great combination of front end client-side design flexibility and back end server-side scripting capabilities.
Friday, February 19, 2010
How to: use XSLT in a semantic web application
An updated version of this blog post is now available as a chapter in the TopBraid Application Development Quickstart Guide (pdf).
XML-based tools form the plumbing of modern electronic publishing systems, so when your semantic web application can create XML, it can easily feed content into one of these systems. The W3C standard XSLT is the most popular tool for converting one kind of XML into another, so in this posting we'll see how SPARQLMotion scripts can use XSLT to create customized XML from your triples. (TopBraid Suite is also very good at reading XML; see the TopBraid Composer help panel "Creating, Importing, Querying, Saving XML documents with Semantic XML" for more on this.) Our example script will save its output as an XHTML file, but you can create XML conforming to any DTD or schema you like and save it as a file or return it via a web service.Creating XML
TopBraid offers several ways to create XML. The Semantic XML feature lets you read arbitrary XML and gives you fine-grained control over XML that you create, but for a quick conversion of data to XML, there are simpler options. The W3C's RDF/XML serialization standard is the most well-known (if not the most popular) format for representing triples in XML, but its flexibility in the representation of triples can add complexity to the XSLT stylesheet, which must account for several possible locations of a given triple's subject, predicate, and object in various combinations of XML elements and attributes.
The simplest, most straightforward XML format that a semantic web application can create is the W3C standard SPARQL Query Results XML Format. For example, with the following query against the kennedys.owl file included with TopBraid Composer,
PREFIX k: <http://topbraid.org/examples/kennedys#>
SELECT ?last ?first ?birth
WHERE {
?s k:lastName ?last .
?s k:firstName ?first .
?s k:birthYear ?birth .
}
ORDER BY (?birth)
the XML representation of the result will have the following structure, with a head element listing the variables followed by a results element that contains a result child for each row of results returned by the SPARQL engine:
As we'll see, a very brief XSLT stylesheet can handle this.
<sparql xmlns="http://www.w3.org/2005/sparql-results#">
<head>
<variable name="last"/>
<variable name="first"/>
<variable name="birth"/>
</head>
<results>
<result>
<binding name="last">
<literal>Kennedy</literal>
</binding>
<binding name="first">
<literal>Joseph</literal>
</binding>
<binding name="birth">
<literal datatype="http://www.w3.org/2001/XMLSchema#integer">1888</literal>
</binding>
</result>
<result>
<binding name="last">
<literal>Fitzgerald</literal>
</binding>
<binding name="first">
<literal>Rose</literal>
</binding>
<binding name="birth">
<literal datatype="http://www.w3.org/2001/XMLSchema#integer">1890</literal>
</binding>
</result>
<!-- more result elements -->
</results>
</sparql>
Creating an XML version of SPARQL query results in a SPARQLMotion script
In our sample application, the XSLT stylesheet will create an XHTML version of the data returned by the query above.
Start by creating a SPARQLMotion File in TopBraid Composer file called xsltdemo. Create a SPARQLMotion script in this file with an ImportRDFFromWorkspace initial module named GetKennedyData, and set its sml:sourceFilePath property to /TopBraid/Examples/kennedys.owl. (For more details on following these steps, see How to: create and run a SPARQLMotion script.)
For your script's second module, drag a SerializeSPARQLResults module from the SPARQLMotion palette's Text Processing section onto the workspace and name it SelectRptData. Set the following three properties to configure it:
Set its sml:selectQuery property to the SPARQL query shown above.
Set sm:outputVariable, a property that names the variable that will hold the results of the query, to queryResults.
For the sml:serialization property, click the white triangle to display the context menu and select Add Existing, because you want to pick from the predefined list of legal values. On the Add existing dialog box, select sm:XML on the right. (If you click on sml:RDFSerialization on the left of this dialog box, you'll see that this module can also output N3, NTriples, RDF/XML, and Turtle RDF.)
Close the Edit SelectRptData dialog box and connect the GetKennedyData module's icon to the SelectRptData one.
When you develop an XSLT stylesheet, you want some sample input XML data handy to test it, so let's have this script create a file for this. Add an Export to XML File icon from the Export to Local section of the palette and call it SaveTestXML. Set its sml:xml property to {?queryResults} to get the data that your SelectRptData module stored in this variable, and set sml:targetFilePath to testdata.xml. That's all you need to set, so connect your SelectRptData icon to it as shown here:
Select that third icon and click the debug icon at the top of the SPARQLMotion workspace to run it, and you should see a testdata.xml file appear in the same directory as your script. This file will have XML that follows the structure of the example shown above.
Applying an XSLT stylesheet in a SPARQLMotion script
First, you need to create the XSLT stylesheet file. If you're using an Eclipse-based XML editor such as oXygen or XML Spy, go ahead and use one of those editors. Otherwise, after selecting the folder in the Navigator view where you want to store the file, pick New from the File menu. Because you're not creating one of the specialized files that TopBraid Composer typically deals with, pick Other from the cascade menu. Pick XML from the XML section of the New dialog box and click next. Call the file createKennedyHTMLRpt.xsl, and click Finish on the New XML File dialog box. (Clicking Next on that dialog would lead to wizards that make the process more complicated than this example requires.) Paste the following stylesheet, which I wrote to process the testdata.xml file created above, onto the editor and save the stylesheet:
(If you create the stylesheet outside of TopBraid Composer, make sure to put it in the same folder as your script, then right-click the folder's icon in the Navigator view and select Refresh so that Eclipse knows that the new file is there.) The stylesheet converts the XML into an XHTML file with a table that has a row for each row of the result set.
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:sp="http://www.w3.org/2005/sparql-results#"
xmlns="http://www.w3.org/1999/xhtml">
<xsl:template match="sp:sparql">
<html>
<head><title>XSLT demo</title></head>
<body>
<table border="1">
<tr>
<th>Last Name</th>
<th>First Name</th>
<th>Birth</th>
</tr>
<xsl:apply-templates/>
</table>
</body>
</html>
</xsl:template>
<xsl:template match="sp:result">
<tr>
<td><xsl:value-of select="sp:binding[@name='last']"/></td>
<td><xsl:value-of select="sp:binding[@name='first']"/></td>
<td><xsl:value-of select="sp:binding[@name='birth']"/></td>
</tr>
</xsl:template>
</xsl:stylesheet>
The next module to add to the SPARQLMotions script is the one that applies the stylesheet to the XML. Drag a Convert XML by XSLT module from the XML Processing section of the palette, name it CreateHTML, and configure it by setting the following three properties:
Set sm:outputVariable to HTMLResult. This variable will store the result of the XSLT transformation.
Set sml:template to {?stylesheet}. We haven't added the script module that sets this variable yet, but will soon.
Set xml:xml to {?queryResults}. As we saw above, the SelectRptData module stores the XML of the query results in this variable; the SaveTestXML module also used the contents of this variable.
Connect the SelectRptData module to your new CreateHTMLRpt module. SelectRptData is already connected to SaveTestXML, but sending a module's output to multiple modules is a common technique in SPARQLMotion scripts.
To read the createKennedyHTMLRpt.xsl stylesheet disk file and send its contents to the CreateHTMLRpt module for use in the XSLT transformation, drag an ImportTextFile module from the Import from Local section of the palette and name it ReadXSLTStylesheet. Tell it where to find the stylesheet file by setting its sml:sourceFilePath property to createKennedyHTMLRpt.xsl, and then set its sm:outputVariable property to stylesheet—the variable that the CreateHTMLRpt module will expect to find the text of the stylesheet that it applies to the output of the SelectRptData module. Connect the ReadXSLTStylesheet module to the CreateHTMLRpt module.
The last module will save the results of the XSLT transformation in a disk file. Drag another ExportToXMLFile module from the Export to Local section of the palette and name it SaveHTMLFile. Set its sml:xml property to {?HTMLResult} so that it reads the variable set by the CreateHTML module, and then indicate where to save this variable's value by setting the module's sml:targetFilePath property to KennedyRpt.html. Connect the CreateHTML module to the new SaveHTMLFile module. Your completed script should look something like this:
To test it, select the CreateHTML icon and click the debug icon. You should see a KennedyRpt.html file appear in the same directory as your xsltdemo script; in a browser, this HTML file will look like this:
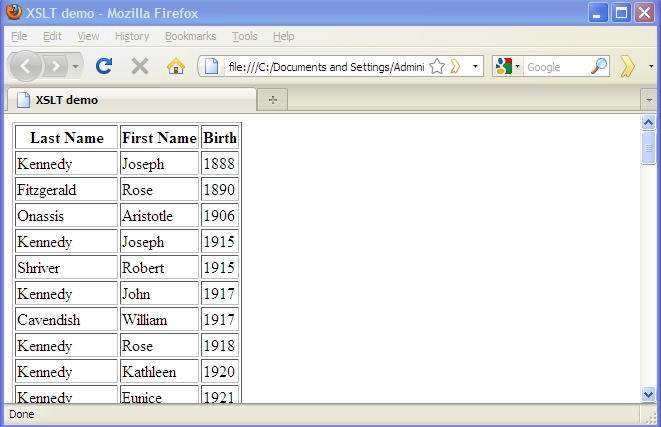
Now that the script is applying the XSLT stylesheet to the XML and creating the HTML, you can right-click your SaveTestXML script module and select Delete to remove it from your script if you want to, but maybe you don't want to—if you ever need to refine the SELECT query in the SelectRptData module or the XSLT stylesheet that the ReadXSLTStylesheet module feeds to the CreateHTML module, the ability to create another disk file of test data may prove handy in the future.
This also demonstrates another technique of sophisticated SPARQLMotion scripts: the ability to share common processing modules for different output modules. You essentially have two SPARQLMotion scripts here—SaveTestXML and SaveHTMLFile—which share several modules. That's why, when you pick Edit SPARQLMotion Script or Execute SPARQLMotion Modules from the Scripts menu, you'll see these two "scripts" listed as choices, even though they're graphically represented as a single flow chart with a choice of end points.
Taking it further
If you had created this script as a web service, then instead of ending with an Export to XML File module from the Export to Local section of the palette, you could route the XML from the Convert XML by XSLT module to a Return XML module from the Export to Remote section of the palette. (Or, that could be a third endpoint added to the two discussed above!) If you set the Return XML module's sml:mimetype property to text/html and had it return XHTML like the xsltdemo script above does, you'd be setting up the dynamic creation of a web page, so that users browsing to the URL that invokes the service would think that they were just linking to a web page.
Of course, it doesn't have to return HTML. It can return anything that an XSLT script can create, and you can set sml:mimetype to any valid HTTP MIME type, and any application that can do an HTTP GET can request delivery of this data, which opens up a wide range of possibilities for the contributions that this application can make to a larger system.


