Convert UML to OWL - why would you ever want to do this? One reason suffices: many enterprise models, that serve as either standards or enterprise schemas, are specified in UML. Increasingly, there is interest in having content of UML models re-purposed in RDF/OWL and the need for RDF/OWL to interoperate with systems built from UML Models.
UML Models are notoriously hard to exchange between UML tools, let alone be transformed into OWL. The exchange format XMI is not only is difficult to understand but also has vendor-specific extensions. The vagaries of MOF, CMOF and EMOF create their own challenges. Nonetheless we have done transformations of UML to OWL. Using a model-based transformation approach, based on SPARQL Rules, XMI models of UML models can be converted to OWL. UML class diagrams can be represented in OWL without information loss. The inverse, however, is not true and will require another blog series.
UML to OWL - Part 1 Contents
Part 1 of the series explains the basis of the approach. The complete series of blogs, as currently conceived, is as follows:
- Converting UML Models to OWL - Part 1: The Approach
- Converting UML Models to OWL - Part 2: Transforming UML Models to OWL Using SPARQL
- Converting UML Models to OWL - Part 3: Examples of Industry UML Model Transformations
The content of this blog is organized as follows:
- Goals, Objectives and Requirements
- Backgrounder on XMI
- Backgrounder on MOF
- Solution Outline
- Overview of Semantic XML
- OCMOF - the OWL Representation of CMOF
- How the Transformations from UML to OWL Work
- Generation of UML Metaclasses
- Generation of UML Classes
- Generation of UML Class Superclass Relationships
- Generation of UML Packages
- Generation of UML Package Relationships
- Performance
- Concluding Remarks
Readers who are very interested in the detailed technical approach, should read all sections of this blog in order. Those who just need to have an overview of the approach could skip sections 9 through 12. Those who have deep knowledge of XMI and MOF may want to skip sections 2 and 3, but I would welcome their feedback on the accuracy of my statements.
Note that some diagrams may be too small to be viewed in the body of the document. Clicking on such a diagram will open a new window with a larger depiction of the diagram.
Goals, Objectives and Requirements
The OWL Models must faithfully represent packages and the logical models or class diagrams. Out of scope, currently, are all of the other UML models such as Interaction Diagrams and State Diagrams. The approach must be able to convert UML by processing XMI files from specific tools. This requires a strategy for converting from the XML structures of XMI to OWL models.
Backgrounder on XMI
XMI, the
XML Metadata Interchange standard is a serialization format for UML Models. The main purpose of XMI is to define how the XML elements are organized within an XMI file. The XMI spec also defines a mechanism for how one XMI element references another, within and across XMI files. Such a mechanism is needed as it is a legal scenario for a single UML model to be serialized to more than one XMI file.
Backgrounder on MOF
MOF began at the time of
CORBA and the need for IDL interfaces. MOF 1.4 resulted in its mapping to Java being codified in the
Java Community Process (JCP) as the
Java Metadata Initiative (JMI). MOF 2.0 was developed in tandem with UML 2.0. The separation of MOF into EMOF and CMOF was motivated by the influence of EMF's Ecore, and model-driven Java development. CMOF was more the motivation of meta model developers. CMOF stands for
Complete Meta Object Facility and is an OMG standard for the UML 2 model interchange. More information can be found at
this page on the
OMG Website.
CMOF includes fully fledged associations, association generalization, property subsetting and redefinition, derived unions, and package merge. Typical XMI container structures look like the example below, from the CMOF UML Infrastructure Model. The basic idea is that a packagedElement owns other elements. A type attribute specifies the type of the packagedElement.
Things get a little busy with how IDs are used for associations and their member ends. That complication, we can leave for Part 2.
<?xml version="1.0" encoding="UTF-8"?>
<xmi:XMI xmi:version="2.1" xmlns:xmi="http://schema.omg.org/spec/XMI/2.1"
xmlns:cmof="http://schema.omg.org/spec/MOF/2.0/cmof.xml">
<cmof:Package xmi:id="_0" name="InfrastructureLibrary">
<ownedMember xmi:type="cmof:Package" xmi:id="Core" name="Core">
<ownedMember xmi:type="cmof:Package"
xmi:id="Core-Abstractions" name="Abstractions">
<packageImport xmi:type="cmof:packageImport"
xmi:id="Core-Abstractions-_packageImport.0"
importedPackage="Core-PrimitiveTypes"
importingNamespace="Core-Abstractions"/>
<ownedMember xmi:type="cmof:Package"
xmi:id="Core-Abstractions-Ownerships" name="Ownerships">
<packageImport xmi:type="cmof:packageImport"
xmi:id="Core-Abstractions-Ownerships-_packageImport.0"
importedPackage="Core-Abstractions-Elements"
importingNamespace="Core-Abstractions-Ownerships"/>
<ownedMember xmi:type="cmof:Class"
xmi:id="Core-Abstractions-Ownerships-Element" name="Element" isAbstract="true">
<ownedComment xmi:type="cmof:Comment"
xmi:id="Core-Abstractions-Ownerships-Element-_ownedComment.0"
annotatedElement="Core-Abstractions-Ownerships-Element">
<body>An element is a constituent of a model.
As such, it has the capability of owning other elements.</body>
</ownedComment>
<ownedRule xmi:type="cmof:Constraint"
xmi:id="Core-Abstractions-Ownerships-Element-not_own_self"
name="not_own_self" constrainedElement="Core-Abstractions-Ownerships-Element"
namespace="Core-Abstractions-Ownerships-Element">
<ownedComment xmi:type="cmof:Comment"
xmi:id="Core-Abstractions-Ownerships-Element-not_own_self-_ownedComment.0"
annotatedElement="Core-Abstractions-Ownerships-Element-not_own_self">
<body>An element may not directly or indirectly own itself.</body>
</ownedComment>
<specification xmi:type="cmof:OpaqueExpression"
xmi:id="Core-Abstractions-Ownerships-Element-not_own_self-_specification">
<language>OCL</language>
<body>not self.allownedElements()->includes(self)</body>
</specification>
</ownedRule>
...
<ownedAttribute xmi:type="cmof:Property"
xmi:id="Core-Abstractions-Ownerships-Element-ownedElement"
name="ownedElement" type="Core-Abstractions-Ownerships-Element"
upper="*" lower="0" isReadOnly="true" isDerived="true"
isDerivedUnion="true" isComposite="true"
association="Core-Abstractions-Ownerships-A_ownedElement_owner">
<ownedComment xmi:type="cmof:Comment"
xmi:id="Core-Abstractions-Ownerships-Element-ownedElement-_ownedComment.0"
annotatedElement="Core-Abstractions-Ownerships-Element-ownedElement">
<body>The Elements owned by this element.</body>
</ownedComment>
</ownedAttribute>
...
Figure 1: A sample of XMI
For more background on the history of MOF the following references may be of value: MOFLON, and Wikipedia.
 Top
TopSolution Outline
Model-based transformation is the central idea of the approach. To implement it we have developed a metamodel of CMOF in OWL. Our strategy is to get out of XML into RDF Triples as soon as possible. Using an ontology of XML we convert XMI into a composite model of triples. XML is a simple enough structure for the composite object pattern - elements contain elements and elements have attributes. XML elements and attributes that make up the XMI file are transformed into OWL instances of the CMOF metamodel. Once we have the XMI in triples we can map constructs to classes and properties of a CMOF metamodel. This model then serves as the generator for model-based transformations to an OWL model of the UML.
Once these instances are loaded as "raw" RDF, rules fire to perform the transformations. Rules are associated with classes to ensure that instances of those classes are processed in an execution sequence. Using SPARQL Rules (SPIN), instances of a class are each processed through a binding mechanism specified by ?this variable. SPARQL Rules can be considered an approach that is similar to, or can be compared with, UML's Object Constraint Language (OCL) and the Query/View/Transformation (QVT) approach to transformations.
The benefits of the OWL and SPARQLRules model-based approach to transformation are:
- Intimacy of the rules with RDF/OWL - triples are evaluated directly
- Understandability - rules are smaller and expressed in the relevant contexts of the model
- Enhanced Performance - evaluation of rules is localized to relevant instances
- Customizability and Evolvability – transformations can be changed by modifying models and/or SPARQL rules
- Ease of maintenance - rules are associated with the constructs they operate over
TopOverview of Semantic XML
XMI is imported into the CMOF metamodel using TopBraid Composer's
Semantic XML as a mapping method. With Semantic XML, TopBraid can automatically generate an OWL/RDF ontology from any XML file. Each distinct XML element name is mapped into a class, and the elements themselves become instances of those classes. A datatype property is generated for each attribute. Nesting of XML elements is represented in OWL using a
composite:child property - an object pattern in OWL that is described at
this blog entry.
The key idea of Semantic XML is that each of the generated OWL classes and datatype properties is annotated with an annotation property, sxml:element and sxml:attribute, respectively. These properties relate the OWL concepts to the XML serialization. Note that these annotations are also used if an OWL model needs to be serialized back to XML format.
If you import an XML file into an ontology that already contains classes and properties with Semantic XML annotations, then the loader will reuse those. The mapping is bi-directional and loss-less so that files can be loaded, manipulated and saved without losing structural information.
A video explaining how Semantic XML works is available at
this link.
OCMOF - the OWL Representation of CMOF
The strategy for the transformation can be summarized as follows:
- Use OWL classes to represent XMI Element Types
- Use SPARQL Rules on those classes to generate CMOF Metaclasses
- Use Metaclasses to make OWL Classes that represent the UML Model
An OWL metamodel of CMOF represents the kinds of containers, elements and attributes shown above. The metamodel was built by studying the UML Metamodel of UML 2.0 - the original motivation for this was to have an automated way of dealing with changes to UML. That will be a future consideration, for now this has proven to be a valuable way of doing verification and validation. The UML metamodel will be covered in Part 2 of this blog series, for Part 1, it is instructive perhaps to show a small piece of the XMI. Below is the XMI for
Basic-Property from the UML model
infrastructure.cmof.xmi.
<ownedAttribute xmi:type="cmof:Property"
xmi:id="Core-Basic-Class-ownedAttribute" name="ownedAttribute"
type="Core-Basic-Property" isOrdered="true"
upper="*" lower="0" isComposite="true"
association="Core-Basic-A_ownedAttribute_class">
<ownedComment xmi:type="cmof:Comment"
xmi:id="Core-Basic-Class-ownedAttribute-_ownedComment.0"
annotatedElement="Core-Basic-Class-ownedAttribute">
<body>The attributes owned by a class.
These do not include the inherited attributes.
Attributes are represented by instances of Property.</body>
</ownedComment>
</ownedAttribute>
Figure 2: A fragment of the XMI for the UML metamodel
As a example of XMI element mappings, the sxml:element maps the XMI element for ocmof:ownedAttribute as shown in the Turtle extract from the OWL model below.
ocmof:ownedAttribute
a owl:Class ;
rdfs:label "Attribute"^^xsd:string ;
rdfs:subClassOf ocmof:TypedThing , ocmof:NamedThing ;
rdfs:subClassOf
[ a owl:Restriction ;
owl:maxCardinality "1"^^xsd:nonNegativeInteger ;
owl:onProperty ocmof:isComposite
] ;
rdfs:subClassOf
[ a owl:Restriction ;
owl:maxCardinality "1"^^xsd:nonNegativeInteger ;
owl:onProperty ocmof:type
] ;
rdfs:subClassOf
[ a owl:Restriction ;
owl:maxCardinality "1"^^xsd:nonNegativeInteger ;
owl:onProperty ocmof:isDerivedUnion
] ;
rdfs:subClassOf
[ a owl:Restriction ;
owl:maxCardinality "1"^^xsd:nonNegativeInteger ;
owl:onProperty ocmof:isReadOnly
] ;
rdfs:subClassOf
[ a owl:Restriction ;
owl:maxCardinality "1"^^xsd:nonNegativeInteger ;
owl:onProperty ocmof:default
] ;
sxml:element "ownedAttribute"^^xsd:string .
Figure 3: ocmof:ownedAttribute in Turtle
The last line,
sxml:element "ownedAttribute"^^xsd:string, is the mapping.
As a example of XMI attribute mappings, the sxml:attribute maps the XMI attribute for ocmof:isOrdered as shown in the Turtle extract from the OWL model below.
ocmof:isOrdered
a owl:DatatypeProperty ;
rdfs:domain ocmof:ownedAttribute ,
ocmof:ownedParameter ,
ocmof:OwnedEnd ;
rdfs:label "is ordered"^^xsd:string ;
rdfs:range xsd:boolean ;
sxml:attribute "isOrdered"^^xsd:string .
Figure 4: ocmof:isOrdered in Turtle
The last line,
sxml:attribute "isOrdered"^^xsd:string, is the mapping.
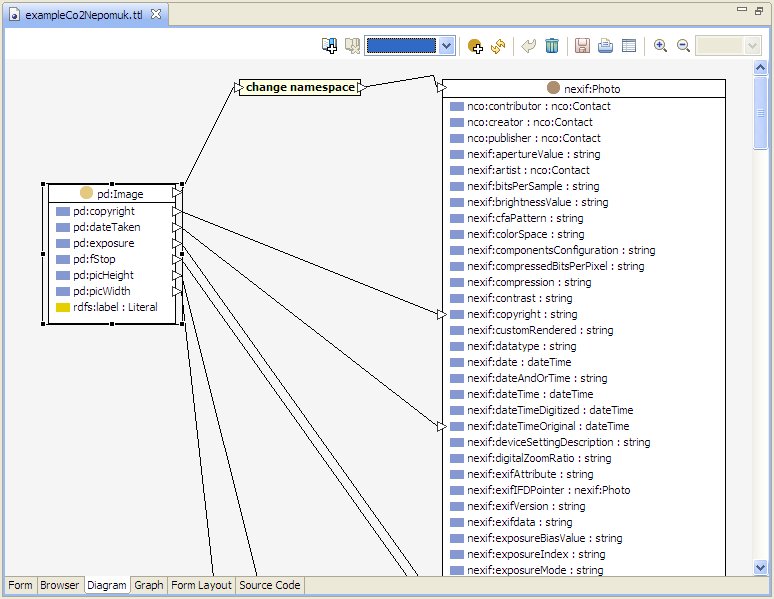
The transformation to OWL results in the following class for uml:Core-Basic-Property.
Clicking on the image will open a larger image in a new window.

Figure 5: A Generated Metaclass Example - uml:Core-Basic-Property
The diagram shows how the datatype properties of the class
uml:Core-Basic-Property correspond to the XMI attributes given in the above fragment. For example
isComposite becomes the property
hasBooleanIsComposite. The prefix
hasBoolean is customizable.
First an OWL model of CMOF XML Elements is used to generate instances of metaclasses to build OWL Classes for XMI Elements. The namespace prefix of ocmof has been used to denote all modeling constructs that makeup the CMOF metamodel. The prefix cmof is the namespace for all constructs generated from the import of the XMI files.
In the diagram below, we show the main classes of the metamodel. Classes like NamedThing and TypedThing have been introduced to optimize the work of the transformers. Constructs in XMI can typically be both named and typed. This kind of multiple inheritance is no problem for the transformations. The diagram is a partial view only. Clicking on the image will open a larger image in a new window.

Figure 6: Some of the classes of the CMOF OWL model
As an alternate view, the diagram that follows is an HTML report of NamedThing in TopBraid Composer. This is automatically generated using SPARQL Web Pages (aka
UISPIN)

Figure 7: OCMOF NamedThing - an abstract class for the transformations
The diagram below shows more details of some
ownedElements. Note how attributes of each of these classes relate to CMOF constructs.

Figure 8: Some "ownedElement" OWL Classes in the OCMOF model
These ocmof classes serve as the starting point for generating ocmof meta-classes and instances of these classes that become the UML model transformed into OWL. The figure below shows the main metaclasses that are generated by rules on the ocmof classes.

Figure 9: The key Meta-classes of the CMOF OWL model
How the Transformations from UML to OWL Work
Model-based transformations use rules associated with OWL Classes. OWL Metaclasses are built using a SPARQL rule for instances of
TypedThing. The names of the metaclasses are determined from the value of the
xmi:type attribute. A number of SPARQL Rules are defined on
TypeThing. Priorities are set by the alphabetic ordering given by the first comment line of the rule. These rules look after the generation of:
- UML Metaclasses
- UML Classes
- UML Class Superclass Relationships
- UML Packages
- UML Package Relationships
Each rule will now be described.
The first task is to create a metaclass and class for every type of element in the ingested XMI file. This is done using the SPARQL Rule below:
# STEP CMOF-SR-001 make UML Metaclass from CMOF type
CONSTRUCT {
?metaClassURI a rdfs:Class .
?metaClassURI rdfs:subClassOf cmof:MetaClass .
?metaClassURI rdfs:label ?metaClassLabel .
?typeURI a owl:Class .
?typeURI a ?metaClassURI .
?typeURI rdfs:subClassOf uml:Construct .
?typeURI rdfs:label ?classLabel .
}
WHERE {
?this xmi:type ?type .
FILTER (?type != "cmof:Property") .
BIND (o2o:localNameOfQName(?type) AS ?name) .
BIND (fn:concat("CMOF ", ?name) AS ?metaClassLabel) .
BIND (fn:concat("UML ", ?name) AS ?classLabel) .
BIND (xmi.common:makeUML-URI(?name) AS ?typeURI) .
BIND (xmi.common:makeCMOF-URI(?name) AS ?metaClassURI) .
}
Figure 10: The SPARQL Rules that make the metaclasses in the OCMOF model
What is going on in these rules? First we explain the "where" clause.
?this xmi:type ?type binds ?this to an instance of TypedThing. For each instance the rule is evaluated.
FILTER (?type != "cmof:Property") blocks further evaluation of the rule if the instance is of type cmof:Property. The reason for this will be explained in Part 2.
BIND (o2o:localNameOfQName(?type) AS ?name) extracts the name of the type from the QName.
BIND (fn:concat("CMOF ", ?name) AS ?metaClassLabel ) builds a label for the metaclass. The function fn:concat is from the JENA SPARQL Library. We use it here to prepend "CMOF" to the name we get from the type of the XMI Element.
BIND (fn:concat("UML ", ?name) AS ?classLabel) makes a class label from the name. We will be constructing both a metaclass and a class from the XMI type. We build a metaclass in order to say what kind of things can happen on the classes. In other words, the generated OWL model is a 3-level ontology. Likewise here we build a label for the UML Class.
BIND (xmi.common:makeUML-URI(?name) AS ?typeURI) builds a URI for the UML Class corresponding to type. This uses a function call to xmi.common:makeUML-URI whose job it is to build the correct namespace path for a UML construct URI. The implementation is shown below.
SELECT ?uri
WHERE {
BIND (xmi.common:baseURI() AS ?baseURI) .
BIND (smf:buildURI("{?baseURI}#{?arg1}") AS ?uri) .
}
where,
smf:buildURI("{?baseURI}#{?arg1}")) builds a URI for the name given in ?arg1 with a base URI supplied by the function xmi.common:baseURI().
BIND (xmi.common:makeCMOF-URI(?name) AS ?metaClassURI ) builds a URI for the metaclass corresponding to type. Likewise this constructs a namspace path for CMOF constructs.
Next we explain what is happening in the head of the rule with the Construct statements. These statements use the generated URIs to create instances of meta-classes and classes.
?metaClassURI a rdfs:Class
gives the metaClass its type.
?metaClassURI rdfs:subClassOf cmof:MetaClass
specifies that the metaclass is a sub-class of cmof:MetaClass - an abstract metaclass for all cmof classes.
?metaClassURI rdfs:label ?metaClassLabel
gives the metaclass a human label.
?typeURI a owl:Class
gives the UML Class a type
?typeURI a ?metaClassURI
gives the UML Class a more specific type so that it can have more properties than owl:Class provides.
?typeURI rdfs:subClassOf uml:Construct
specifies that the UML Class is a subclass of the abstract OWL Class uml:Construct/
?typeURI rdfs:label ?classLabel
gives the UML Class a human label.
Generation of UML Classes
Once we have the necessary metaclasses we can begin the work of creating instances of those classes. These instances will, of course, be classes (the meta-world can get confusing). This work is done the the SPARQL Rule below.
# STEP CMOF-SR-002 make UML Classes from CMOF elements
CONSTRUCT {
?type a rdfs:Class .
?type rdfs:subClassOf cmof:MetaClass .
?class a ?type .
?class rdfs:label ?name .
?class ocmof:hasCMOFbasis ?this .
?superURI a owl:Class .
?superURI a cmof:CategoryClass .
?superURI rdfs:label ?super .
?subURI a owl:Class .
?subURI a cmof:CategoryClass .
?subURI rdfs:subClassOf ?superURI .
?subURI rdfs:label ?sub .
?class rdfs:subClassOf ?mySuperClass .
}
WHERE {
?this xmi:type "cmof:Class" .
?this xmi:id ?name .
BIND (o2o:pathPart(?name, "-") AS ?path) .
OPTIONAL {
?path o2o:pairHyphenIncrementally ( ?super ?sub ) .
BIND (xmi.common:makeUML-URI(smf:buildString("CLASSES_{?super}")) AS ?superURI) .
BIND (xmi.common:makeUML-URI(smf:buildString("CLASSES_{?sub}")) AS ?subURI) .
BIND (xmi.common:makeCMOF-Resource("cmof:Class") AS ?type) .
BIND (xmi.common:makeUML-URI(?name) AS ?class) .
} .
BIND (xmi.common:makeUML-URI(smf:buildString("CLASSES_{?path}")) AS ?mySuperClass) .
}
Figure 11: The SPARQL Rules that make UML Classes
More details of this transformation will be given in Part 2 of this blog series. An interesting aspect of this particular rule to mention now is how it builds deep inheritance structures by using
Property Functions to recurse over hyphenated names (more on the use of Property Functions, also known as Magic Properties, with TopBraid Composer can be found at
this blog entry). These hyphenated names occur throughout the XMI metamodel of UML. For example
Core-Basic-Class looks like:
<ownedMember xmi:type="cmof:Class" xmi:id="Core-Basic-Class" name="Class" superClass="Core-Basic-Type">
<ownedComment xmi:type="cmof:Comment" xmi:id="Core-Basic-Class-_ownedComment.0"
annotatedElement="Core-Basic-Class">
<body>A class is a type that has objects as its instances.</body>
</ownedComment>
<ownedAttribute xmi:type="cmof:Property" xmi:id="Core-Basic-Class-isAbstract"
name="isAbstract" type="Core-PrimitiveTypes-Boolean" default="false">
<ownedComment xmi:type="cmof:Comment" xmi:id="Core-Basic-Class-isAbstract-_ownedComment.0" annotatedElement="Core-Basic-Class-isAbstract">
<body>True when a class is abstract.</body>
</Attribute>
Figure 12: Example of Hyphenated Names in the UML Metamodel
How this is done in the SPARQL Rule is explained briefly below.
In the SPARQL Rule shown above in figure 11, the statement in the tail: ?path o2o:pairHyphenIncrementally ( ?super ?sub ) is a Property Function that returns two results: ?super and ?sub for every hypenated pair.
for each pair the statement: ?subURI rdfs:subClassOf ?superURI in the head of the rule builds superclass relationships.
Generation of UML Class Superclass Relationships
Once we have all of the UML Classes, the next rule can build the
rdfs:subClassOf relationships.
# STEP CMOF-SR-005 - fixup the superclass of the root Classes
CONSTRUCT {
?class rdfs:subClassOf uml:Class .
}
WHERE {
?class a cmof:CategoryClass .
BIND (afn:localname(?class) AS ?className) .
FILTER fn:starts-with(?className, "CLASSES_") .
NOT EXISTS {
?class rdfs:subClassOf ?superClass .
} .
}
The result of executing the preceding UML Class rules is the UML Class Hierarchy shown in the diagram below.

Figure 13: Generated UML Metamodel Class Hierarchy
TopGeneration of UML Packages
# STEP CMOF-SR-020 - make Packages
CONSTRUCT {
?package rdfs:label ?name .
?package ocmof:hasCMOFbasis ?this .
?mySuperClass a owl:Class .
?mySuperClass rdfs:label ?path .
?superURI a owl:Class .
?superURI a cmof:CategoryClass .
?superURI rdfs:label ?super .
?subURI a owl:Class .
?subURI a cmof:CategoryClass .
?subURI rdfs:subClassOf ?superURI .
?subURI rdfs:label ?sub .
?package a ?mySuperClass .
?package a uml:Package .
}
WHERE {
?this xmi:type "cmof:Package" .
?this xmi:id ?name .
BIND (xmi.common:makeUML-URI(?name) AS ?package) .
BIND (o2o:pathPart(?name, "-") AS ?path) .
OPTIONAL {
?path o2o:pairHyphenIncrementally ( ?super ?sub ) .
BIND (xmi.common:makeUML-URI(smf:buildString("PACKAGES_{?super}")) AS ?superURI) .
BIND (xmi.common:makeUML-URI(smf:buildString("PACKAGES_{?sub}")) AS ?subURI) .
} .
BIND (xmi.common:makeUML-URI(smf:buildString("PACKAGES_{?path}")) AS ?mySuperClass) .
}
Generation of UML Package Relationships
# STEP CMOF-SR-024 - fixup the superclass of the root Packages
CONSTRUCT {
?packageClass rdfs:subClassOf uml:Package .
}
WHERE {
?this xmi:type "cmof:Package" .
?package ocmof:hasCMOFbasis ?this .
?package a ?packageClass .
NOT EXISTS {
?packageClass rdfs:subClassOf ?superClass .
} .
}
The result of executing the preceding UML Package rules is the UML Package Hierarchy shown in the diagram below.

Figure 14: Generated UML Metamodel Package Hierarchy
As a measurement of the performance with the TopBraid Composer release 3.4.0, the conversion of the UML Infrastructure XMI took 38.611 seconds and generated 19,575 statements (RDF triples) on a DELL Studio XPS Laptop with 4GB of memory, running Windows 7. This translates to an inference speed of 507 TPS (Triples per second).
Concluding Remarks
Part 1 of this blog has introduced the power of model-based transformation using SPARQL Rules as a means to transform XMI to OWL. Our experience in doing this work confirms the extensibility and flexibility of this approach. The subject is a complex one requiring a grounding in the intricacies of UML Metamodeling, and a knowledge of SPARQL and SPARQL Rules. We have attempted to do that briefly in this blog - not an easy matter.
Part 2 of this blog series will discuss transforming UML Models to OWL Using SPARQL.