
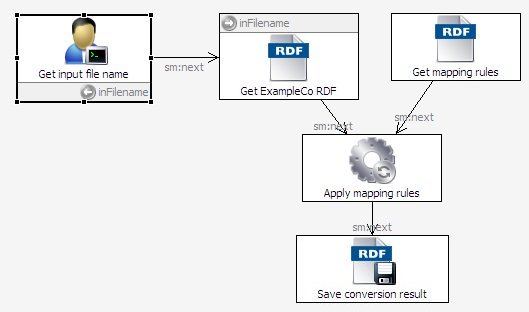
The "Composing the Semantic Web" blog entry SPINMap: SPARQL-based Ontology Mapping with a Graphical Notation describes TopBraid 3.5's new tool for mapping between vocabularies or ontologies. (It also points to a handy video that demonstrates both simple and sophisticated uses of SPINMap.) Once you've created a mapping, though, how do you use it to convert data? As it turns out, no new technology is necessary; SPINMap just creates SPIN rules that you can apply in a SPARQLMotion script. Let's look at an example. Imagine that I'm a publisher who receives images and metadata about those images from ExampleCo every month, and I load these images and metadata into my company's Digital Asset Management system. ExampleCo uses their own vocabulary to describe the metadata, but I prefer to use the NEPOMUK vocabulary for describing image metadata, because I know that by taking advantage of a vocabulary used by other systems around the world, my data can more easily interoperate with other data and tools. Following the steps described in the blog posting mentioned above, I create the mapping from ExampleCo's pd:Image class and its associated properties to the NEPOMUK equivalents. Because the NEPOMUK image vocabulary's nexif:Photo class has so many properties associated with it, the diagram of it doesn't all fit on the screen at once, but it was easy enough scroll up and down as I mapped the pd:Image properties on the left to various NEPOMUK nexif:Photo properties. I saved the mapping in its own file, which I called ExampleCo2Nepomuk.ttl. At this point, I could convert a set of ExampleCo metadata by importing a file of that data and ExampleCo2Nepomuk.ttl into the same model and then picking Run Inferences from the Inference menu, assuming that Configure Inferencing on the same menu had TopSPIN configured as the inferencing engine. I wanted this to be more automated, though, so I put it in a SPARQLMotion script that could be called as a web service or from a TopBraid Ensemble interface. This would make it easier to re-use this mapping every month on each new batch of ExampleCo image data as it comes in: The script's first module prompts for the input filename, because it will be a new dataset each month. This module hands the filename to the "Get ExampleCo RDF" module, an Import RDF From Workspace module that reads in the ExampleCo data. At the same time, another Import RDF From Workspace module named "Get mapping rules" reads in the ExampleCo2Nepomuk.ttl file storing the SPIN-based mapping rules. Both of these modules feed their triples to an Apply TopSPIN module named "Apply mapping rules," which has its sml:replace value set to true so that it only passes along the new triples that it creates and not the input triples. The script's last module saves the result in a disk file, but could easily send it off for addition to a triplestore in a Digital Asset Management system. There's nothing especially new or unusual in this script; what's new is that the rules that it applies to the data were created by a graphical drag-and-drop tool instead of being coded by hand. (Rest assured that the rules stored by the tool are still expressed using standard SPARQL.) With easy data aggregation being one of the great advantages of semantic web applications, it's nice to know that SPINMap lets you define data transformations with less trouble than ever before, making your application development (and application maintenance) even faster. As an added bonus, because the mappings are stored as SPIN rules (also known as SPARQL Rules), they can easily be combined with other SPARQL Rules that you can run with the same script. These other rules might perform validation to ensure that the data being read conforms to certain data quality standards, or they could calculate new values based on a combination of the incoming data and existing stored data.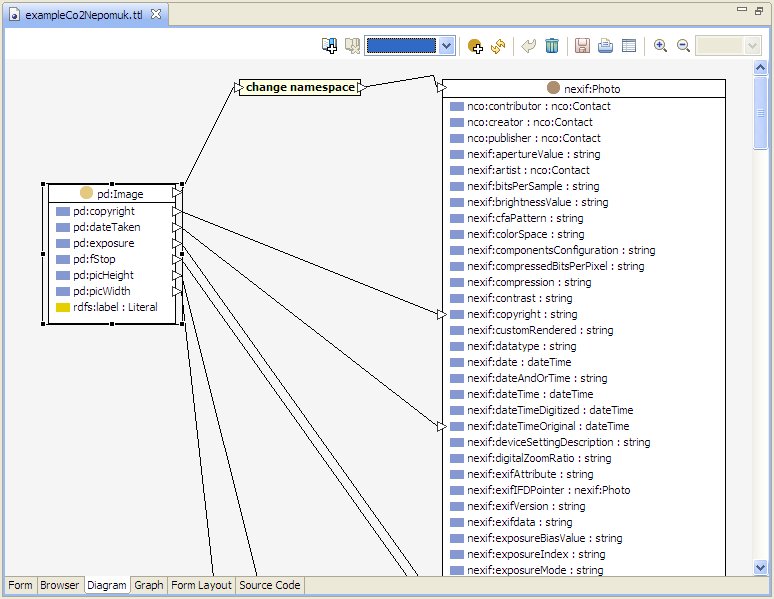
Thursday, July 21, 2011
Putting your drag-and-drop SPINMap vocabulary mappings into production
![]()
Subscribe to:
Post Comments (Atom)



1 comments:
Your photography blog site is really awesome! You've done lots of excellent work! I hope your success.
colour correction
Post a Comment